Main Memory and Virtual Memory

This post provides a high level discussion of main memory and virtual memory. It serves as a summary of the main concepts and key points to know about main memory and virtual memory in the context of operating systems.
Before we start discussing the main memory and virtual memory, let’s first briefly introduce the concept of the main memory and virtual memory.
Main Memory (Primary Storage):
- Main memory, also known as RAM (Random Access Memory), is the primary working storage in a computer.
- It features fast read and write speeds and is used to store programs and data that are currently in use.
- RAM is volatile, meaning the information it holds is lost when the computer is turned off.
- Main memory interacts directly with the CPU, so its performance significantly impacts the overall efficiency of the system.
- The size of main memory is limited and is typically much smaller than a hard drive but has a much faster access speed.
Virtual Memory:
- Virtual memory is a memory management technique that enables the operating system to use space on the hard disk to extend physical memory.
- With virtual memory, each program can assume it has a contiguous, isolated address space, even if the actual physical memory is fragmented or insufficient.
- The virtual memory system divides memory into fixed-size blocks called pages. Similarly, the physical memory is divided into equally sized blocks called page frames.
- When there is not enough physical memory, inactive pages are swapped to a swap file or partition on the hard disk; this process is called paging.
- Virtual memory allows for running larger programs and more programs concurrently without actually increasing the capacity of physical memory.
- Using virtual memory may introduce some overhead because it requires managing page tables, handling page faults, and possibly performing disk I/O operations.
Table of Contents
Main Memory
Background ️and Concepts
Virtual Memory
Background ️and Concepts
Code needs to be in memory to execute, but the entire program is rarely used all at once. Parts of a program such as error-handling code, unusual routines, or large data structures may not be accessed frequently. Therefore, it’s not necessary to have the entire program code loaded into memory simultaneously. Considering this, there should be an ability to execute partially-loaded programs, loading only the required portions.
With virtual memory technology, programs are no longer constrained by the limits of physical memory. Each running program takes up less memory while executing, allowing more programs to run concurrently. This leads to increased CPU utilization and throughput without increasing response time or turnaround time. Less I/O is needed to load or swap programs into memory, which means each user program runs faster.
During discussion, we first define some terminology and then go into the details of virtual memory:
- Page: A fixed-size block of virtual memory, typically several kilobytes (e.g., 4KB), representing the smallest unit that can be independently loaded into memory.
- Page Frame: A fixed-size block within physical memory used to store pages mapped from the virtual address space. Page frames are units into which physical memory is organized.
- Segment: A logical part of a program with variable size. Each segment has its own starting address and length, representing a set of related instructions or data.
- Demand Paging: A memory management strategy where not all pages of a program are loaded into memory at once but only when needed. When a process attempts to access a page not in memory, a page fault occurs, and the OS loads the required page from disk into an available page frame.
-
Demand Segmentation: A memory management strategy based on segments, where each segment represents a logical part of a program. Only the segments that are needed are loaded into memory. Unlike paging, segments do not have a fixed size but are determined by the actual needs of the program.
- Page Table: A data structure maintained by the operating system to manage the mapping from virtual addresses to physical addresses. It contains entries for each page in the virtual address space indicating which physical page frame it corresponds to.
- Memory Management Unit (MMU): A hardware component responsible for translating logical addresses into physical addresses. It uses the page table for address translation and handles page faults.
- Page Fault: An exception that occurs when a process attempts to access a page not present in physical memory. The OS responds to this error by loading the necessary page from disk into memory.
-
Address Mapping Mechanism When a process attempts to access an address, the MMU looks up the corresponding physical address based on the current page table. If the page is not in memory (a page fault occurs), the operating system loads the necessary page from disk into memory and updates the page table.
- Virtual Address Space:
- The virtual address space is the logical address range provided by the operating system for each process. Typically, the logical address space for the stack is designed to start at the maximum logical address and grow “downward,” while the heap grows “upward.” This design maximizes the use of the address space.
- The unused address space between the stack and the heap forms a “hole,” which allows for efficient memory usage. No physical memory is allocated until the heap or stack grows into a new page. This approach enables sparse address spaces with holes left for future growth, dynamically linked libraries, etc.
- System libraries can be shared via mapping into the virtual address space, allowing multiple processes to share a single copy of the library, thus saving memory. Shared memory can be achieved by mapping pages read-write into the virtual address space. Pages can also be shared during the fork() call, speeding up process creation.
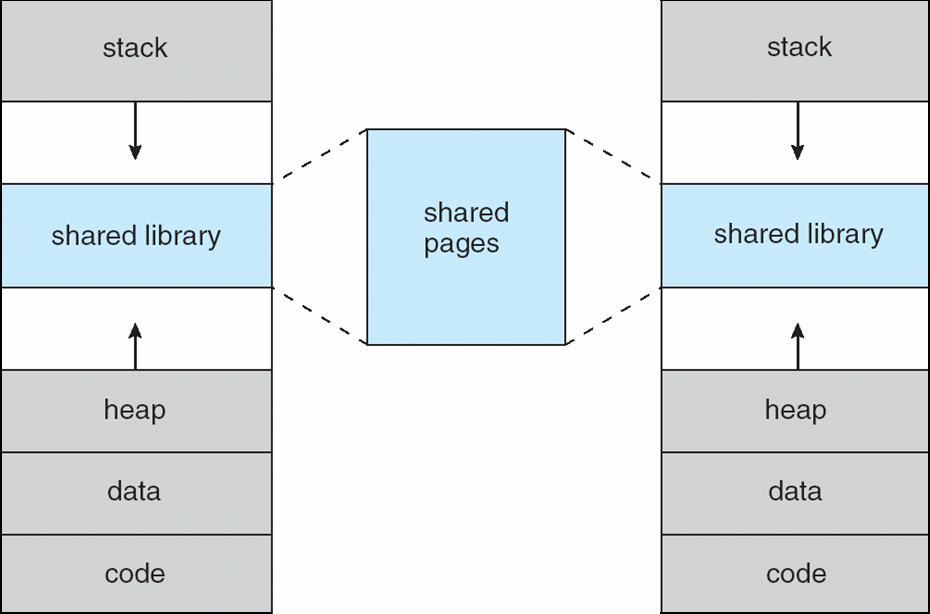
Demand Paging
- Page Replacement with Prediction: In traditional paging systems with swapping, the pager (the component responsible for page management) tries to predict which pages will be used in the future and makes decisions about which pages can be safely swapped out. This guessing is not always accurate and can lead to unnecessary I/O operations and memory wastage.
-
On-Demand Loading in Demand Paging: Conversely, in demand paging systems, the OS does not pre-load pages but only brings them into memory when they are actually needed. This reduces unnecessary I/O operations, improves memory utilization, and speeds up process startup.
- Determining the Set of Pages to Load:
- Working Set Theory: The OS tracks each process’s recent access patterns to estimate its current working set.
- Page Fault Handling: When a process attempts to access a page not in memory, a page fault occurs. The OS catches this fault and loads the required page from disk into memory.
- Page Replacement Algorithms: Algorithms like LRU (Least Recently Used) and FIFO (First In First Out) help decide which pages should remain in memory and which can be removed.
- New MMU Functionality: Modern Memory Management Units (MMUs) provide additional features to support demand paging, such as TLB caching and multi-level page tables, which enhance address translation speed and performance.
- Behavior Based on Page Residency:
- If the Needed Pages Are Already in Memory: There is no difference in behavior between demand paging and non-demand paging systems. The process can directly access the required pages without additional actions.
- If the Needed Pages Are Not in Memory: The OS must detect this situation and load the required page from storage (e.g., disk) into memory. This process is transparent, ensuring that program behavior remains unchanged and programmers do not need to modify their code.
- Transparency: A key characteristic of demand paging is its transparency. Programs run as if they have access to a complete and contiguous address space, without needing to know how memory is managed at the lower levels. The OS and hardware work together to ensure that page loading and unloading are completely transparent to applications, maintaining program consistency and stability.
Demand paging achieves more efficient, flexible memory management and higher system performance by loading pages on-demand rather than relying on predictive methods. It uses working set theory and page fault handling to intelligently determine which pages should be loaded into memory and leverages new MMU functionalities to optimize this process. Additionally, demand paging maintains transparency for applications, allowing developers to benefit from performance improvements without changing their code.
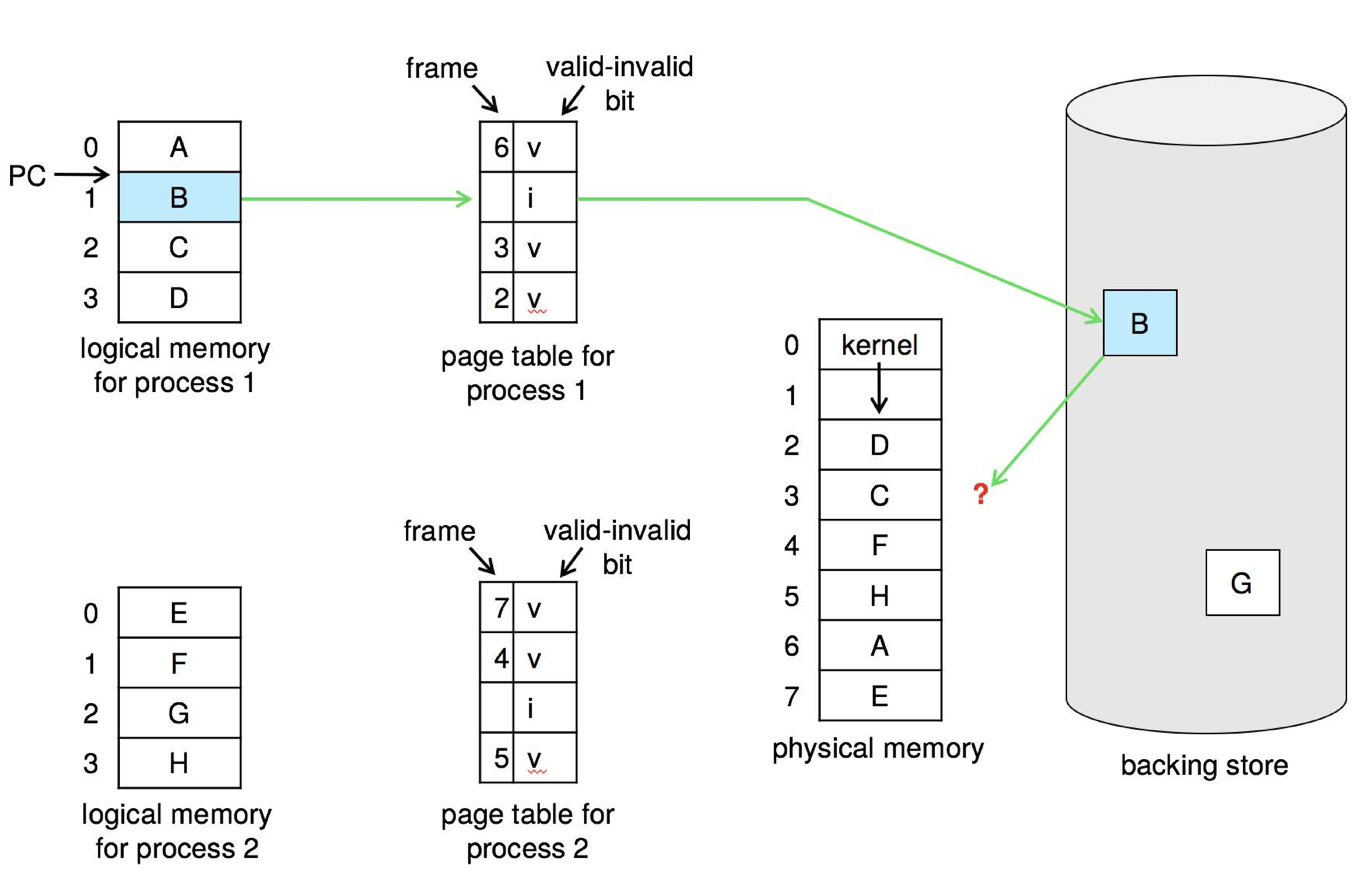
Valid-Invalid Bit
Each page table entry is associated with a valid-invalid bit:
- V (Valid): Indicates that the page is currently in memory (memory resident).
- I (Invalid): Indicates that the page is not in memory.
Initially, the valid-invalid bit for all entries in the page table is set to I, assuming that no pages are in memory at startup.
For example, a snapshot of a page table might look like this:
| Page Number | Frame Number | Valid-Invalid Bit |
|---|---|---|
| 0 | 5 | V |
| 1 | - | I |
| 2 | 7 | V |
| 3 | - | I |
In this example, pages 0 and 2 have their valid-invalid bits set to V, indicating they are in physical memory, while pages 1 and 3 have their bits set to I, indicating they are not currently in memory.
Steps in Handling Page Faults
When a program attempts to access a page, if that page is not in memory, it triggers a page fault. The operating system captures this fault and handles it through the following steps:
- First Reference to the Page: When a process first references a page that is not in memory, it causes a page fault, and control is transferred to the operating system.
- Operating System Check: The operating system checks the page table to decide how to proceed
- Invalid Reference: If the page table entry is marked as invalid (I) due to an illegal address, the process is aborted.
- Just Not in Memory: If the page is simply not in memory but the reference is valid, continue to the next step.
- Find a Free Frame: The operating system needs to find a free frame to hold the incoming page. If all frames are occupied, it selects a page to replace using a page replacement algorithm.
- Swap Page into Frame: The operating system schedules a disk operation to load the required page from disk or swap space into the found free frame.
- Update Page Table: Update the page table entries to indicate that the page is now in memory. Specifically, set the valid-invalid bit to valid (V) and record the corresponding physical frame number.
- Set Validation Bit: Set the validation bit to V, indicating that the page has been successfully loaded into memory.
- Restart the Instruction: Return control to the process that caused the page fault, re-executing the instruction that led to the fault, ensuring the program can continue running normally.
Through these steps, the operating system ensures that only the pages actually needed are loaded into memory, improving memory utilization and reducing unnecessary I/O operations.
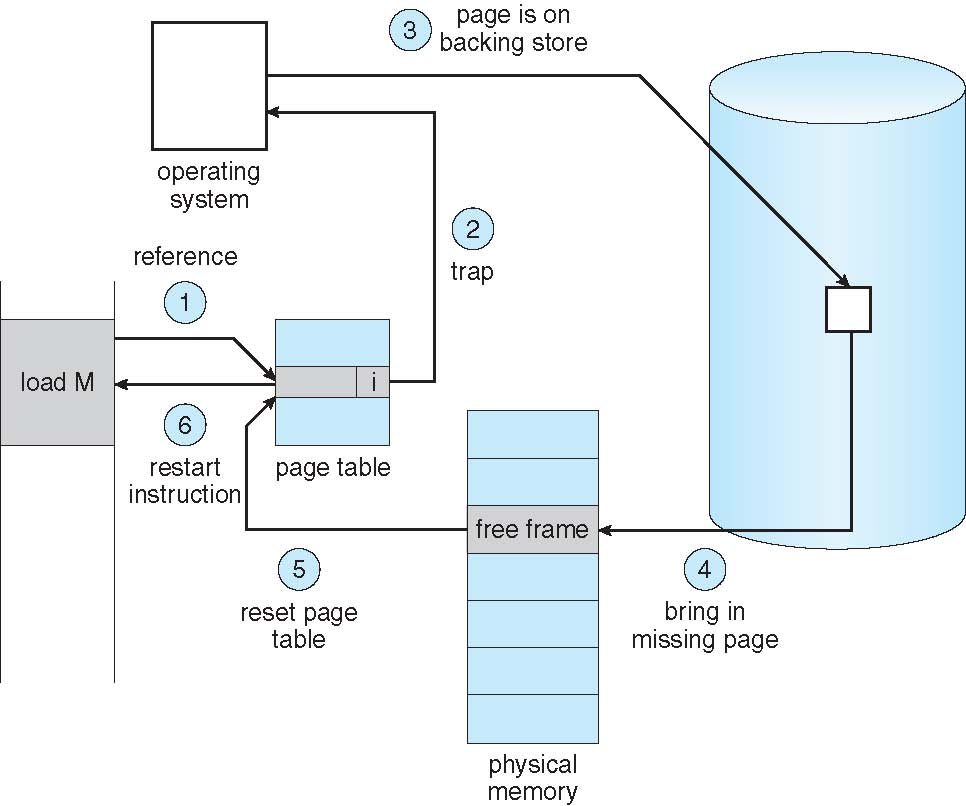
Aspects of Demand Paging
- Extreme Case: Start Process with No Pages in Memory: In a demand paging system, an extreme case is starting a process with no pages in memory. The OS sets the instruction pointer to the first instruction of the process, which is non-memory-resident, leading to an immediate page fault. For every other process page, the same situation occurs on the first access, triggering a page fault.
- Pure Demand Paging: Pure demand paging means that all pages are loaded only when needed. In reality, a given instruction could access multiple pages, resulting in multiple page faults.
- Pain Decreased Because of Locality of Reference: The principle of locality of reference reduces the performance issues caused by frequent page faults. Programs tend to repeatedly access the same or adjacent pages over short periods, allowing the OS to manage memory more efficiently and reduce the number of page faults.
- Hardware Support Needed for Demand Paging:
- Page Table with Valid / Invalid Bit: Each page table entry includes a valid-invalid bit to indicate whether the page is in memory.
- Secondary Memory (Swap Device with Swap Space): The system requires a disk or another form of secondary storage to hold infrequently used pages, enabling them to be reloaded into memory when needed.
- Instruction Restart Mechanism: When a page fault occurs, the OS must be able to recover and re-execute the instruction that caused the page fault, ensuring the program can continue running normally.
- Free-Frame List:
- When a page fault occurs, the operating system must bring the desired page from secondary storage into main memory.
- Most operating systems maintain a free-frame list, a pool of free frames for satisfying such requests.
- Operating system typically allocate free frames using a technique known as zero-fill-on-demand, ensuring the content of the frames zeroed-out before being allocated.
- When a system starts up, all available memory is placed on the free-frame list.

Through these mechanisms, a demand paging system can efficiently manage and allocate memory under limited resources, minimizing the impact on program performance.
Stages in Demand Paging
In a demand paging system, when a page fault occurs, the operating system needs to execute a series of operations to handle this situation. Below are the detailed steps involved in handling a page fault, especially in the worst case:
- Trap to the Operating System: When a process accesses a non-resident page, it triggers a page fault, transferring control to the OS.
- Save User Registers and Process State: The OS saves the current process’s registers and state for later restoration.
- Determine That the Interrupt Was a Page Fault: The OS confirms the interrupt was caused by a page fault.
- Check Legality and Locate Disk Position: The OS verifies the page reference is legal and identifies its location on disk or swap space.
- Issue a Read from Disk to a Free Frame: The OS schedules a disk read to load the required page into a free frame.
- Wait for Device to Service Read Request: The request waits in queue and for disk seek/latency before data transfer starts.
- Begin Transfer of Page to Free Frame: The disk transfers the page to a free frame, while the OS allocates the CPU to other processes.
- Receive Interrupt from Disk I/O Subsystem: Upon completion, the disk sends an interrupt, and the OS saves the state of the current process.
- Confirm Interrupt Came from Disk: The OS confirms the interrupt originated from the disk I/O subsystem.
- Update Page Table and Other Tables: The OS updates the page table and related tables to reflect the page is now in memory.
- Wait for CPU Reassignment: The OS reassigns the CPU back to the process that caused the page fault.
- Restore User Registers, Process State, and Resume Execution: The OS restores the saved state and re-executes the interrupted instruction.
In the worst case, handling a page fault involves multiple stages, including capturing the fault, saving state, checking legality, issuing read requests, waiting for disk service, processing interrupts, updating tables, and finally restoring and re-executing instructions. These steps ensure that even under extreme conditions, the operating system can effectively manage and respond to page faults, ensuring program correctness and system efficiency.
Performance of Demand Paging
Demand paging is a method used in virtual memory management that allows an operating system to load only the necessary parts of a process into physical memory rather than loading the entire process at once. This approach leads to more efficient use of limited physical memory resources and supports larger address spaces than available physical memory.
When discussing the performance of demand paging, three major activities can impact its efficiency:
- Servicing the interrupt: When a page fault occurs, the CPU triggers an interrupt. The operations involved in this process are usually handled by carefully written code, requiring just a few hundred instructions, which takes relatively little time.
- Reading the page: This is the most time-consuming part because it involves reading data from disk to memory. Disk I/O operations are significantly slower compared to CPU and memory accesses.
- Restarting the process: After handling the page fault, the system needs to restore the state of the process and continue execution. This also requires a relatively short amount of time.
Page Fault Rate
The page fault rate $p$ represents the probability of a page fault occurring with each memory access, where $0 \leq p \leq 1$. If $p = 0$, no page faults occur; if $p = 1$, every memory reference results in a page fault.
Effective Access Time (EAT)
Effective Access Time refers to the actual average time required for a single memory access, which depends on the page fault rate and the additional overhead incurred when handling page faults. The EAT can be calculated using the following formula:
\[EAT = (1 - p) \times \text{memory access time} + p \times (\text{page fault overhead} + \text{swap page out time} + \text{swap page in time})\]Where:
- $\text{memory access time}$ is the time for a normal memory access.
- $\text{page fault overhead}$ is the fixed cost associated with handling a page fault.
- $\text{swap page out time}$ and $\text{swap page in time}$ refer to the time taken to swap a page out of memory and to swap a page into memory from disk, respectively.
Swap Space I/O vs File System I/O
Swap space I/O operations are generally faster than file system I/O even if they reside on the same device. This is because swap space is allocated in larger chunks, reducing the need for management. Moreover, at process load time, the entire process image can be copied to swap space, from which pages can then be swapped in and out as needed.
Older versions of BSD Unix used to copy the whole process image to swap space. In contrast, Solaris and current BSD versions prefer to demand-page in from the program binary on disk but discard pages instead of swapping them out when freeing frames.
Pages not associated with any files, such as those for the stack and heap, are called anonymous memory. There are also pages that have been modified in memory but have not yet been written back to the file system.
Mobile Systems
Mobile systems typically do not support traditional swapping mechanisms. Instead, they rely on demand paging from the file system and reclaim read-only pages (such as code segments). This approach works without a dedicated swap partition and is better suited to the characteristics of mobile devices, such as limited storage space and battery life.
Copy-on-Write
Copy-on-Write (COW) is an optimization technique used in the creation of child processes to save memory and speed up process creation. When a process (the parent) creates another process (the child), both processes initially share the same memory pages. Pages are only actually copied when one of the processes attempts to modify the data contained within these shared pages. The new page then becomes exclusive to the process that attempted the modification. This method reduces unnecessary memory copy operations because often the child process will quickly execute a new program (via an exec() system call), thus abandoning the parent’s address space.
Advantages of COW
- More efficient process creation: By copying pages only when necessary, COW can significantly reduce the resources and time required to create a child process.
- Zero-fill-on-demand pages: Generally, free pages are allocated from a pool of pages that have been pre-filled with zeros. This ensures that before being allocated to a process, the page content is safe and uninitialized data has been cleared.
- Fast demand page allocation: To ensure fast demand paging execution, the pool should always have free frames available. Ideally, we do not want to have to free a frame as well as perform other processing on a page fault.
- Why zero-out a page before allocating it?: Before allocating a page to a process, its contents are set to zero for security and consistency. It ensures that a new process does not inadvertently access old data, which is especially important in multi-user systems or environments running untrusted code.
When the fork() system call is used to create a child process, the parent process is not suspended. However, when it comes to the vfork() system call, the situation is different. After vfork() is called, the parent process is suspended until the child either calls exec() to start a new program or calls _exit() to terminate itself. This is because vfork() does not create a full, separate copy of the address space; instead, the child shares the address space with the parent and operates under Copy-on-Write (COW) semantics. This makes vfork() more efficient in terms of resource utilization compared to fork(), but it also requires that the child relinquish use of the parent’s address space as soon as it has completed its necessary operations.
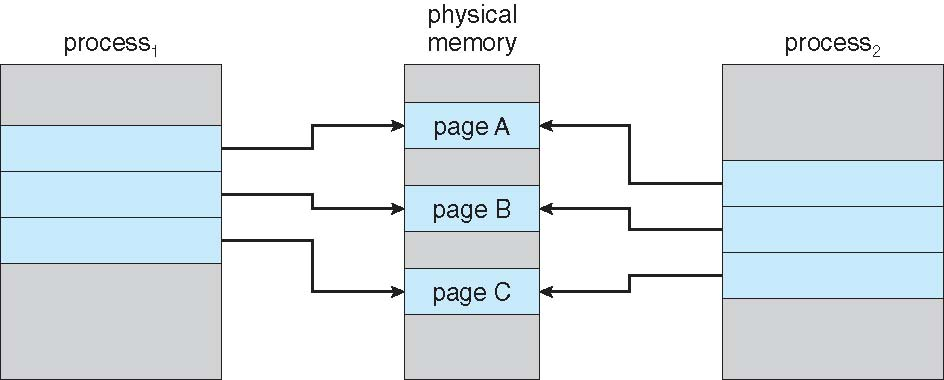
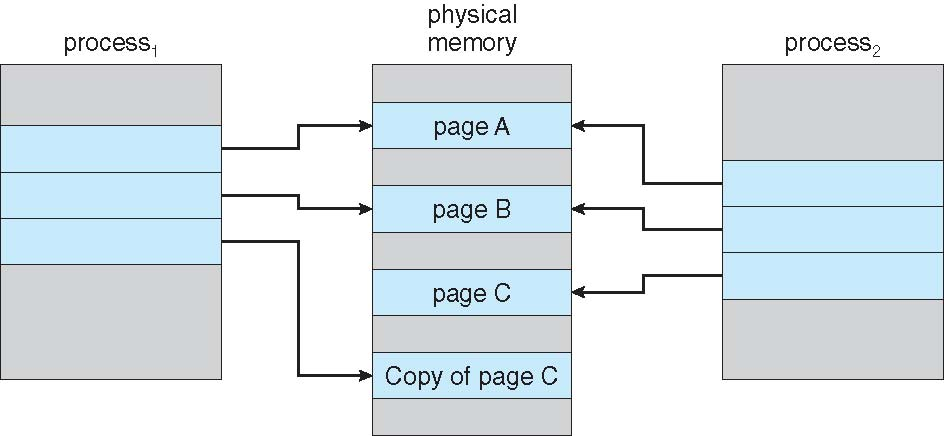
Page Replacement
When there are no free physical frames in the system, it means all of the physical memory has been allocated to process pages, the kernel, I/O buffers, etc. In this scenario, if a new page needs to be loaded into memory, the operating system must decide how to handle this situation. This usually involves choosing a page replacement algorithm.
Page replacement refers to the process of selecting a page currently in memory to evict (swap out) to make room for the new page. The chosen page can belong to any process or even the kernel itself. Deciding which page to replace is critical because poor choices can lead to performance degradation, such as an increased number of page faults, where pages are frequently swapped in and out of memory.
Basic Replacement Policies
Page replacement is a critical mechanism in the memory management of an operating system that helps prevent the over-allocation of physical memory. When a process tries to access a page that is not present in physical memory, a page fault occurs. At this point, the operating system must decide how to handle this fault, and if there are no free physical frames available, it must choose one of the pages already in memory for replacement.
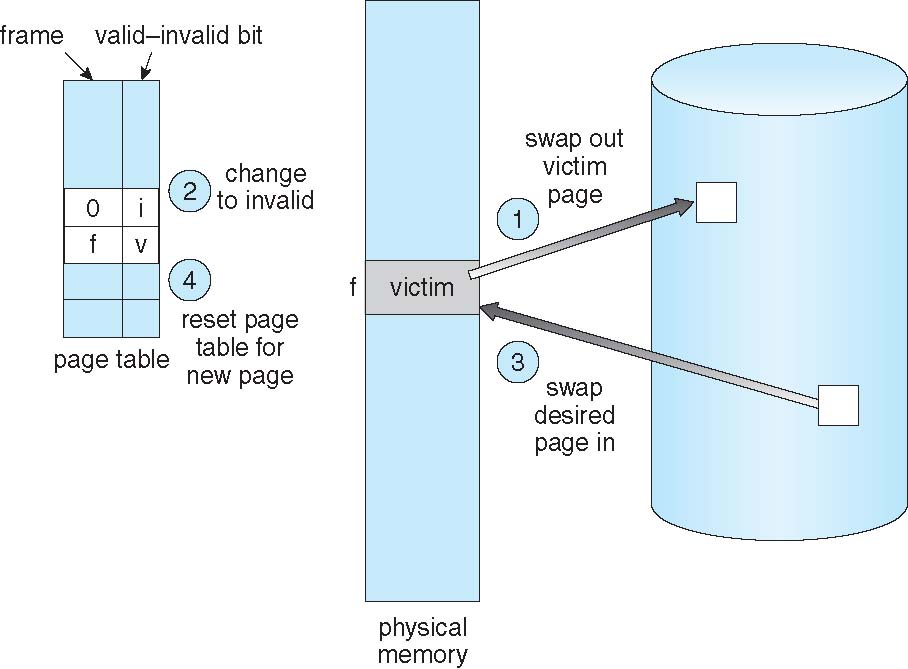
The basic page replacement process is a sequence of steps taken when a process needs to access a page that is not currently in physical memory. This process typically involves the following stages:
-
Find the location of the desired page on disk: The operating system must know which part of the disk contains the page it needs to load.
- Find a free frame:
- If there is a free frame available, use it.
- If no free frames are available, a page replacement algorithm is used to select a victim frame. A victim frame is one that will be removed from physical memory to make space for the new page.
-
If the victim frame is dirty (modified), it must be written back to disk to ensure data consistency.
-
Bring the desired page into the (newly) free frame, and update the page and frame tables so they reflect the new mapping.
- Continue the process by restarting the instruction that caused the trap: This means re-executing the instruction that led to the page fault to allow the process to continue its execution.
It’s important to note that during the handling of a page fault, there may now be potentially two page transfers – one to write out the victim page to disk (if it is dirty), and another to read in the required page from disk to memory. This increases the effective access time (EAT), which refers to the actual average time for each memory access.
Frame allocation and page replacement algorithms are two key concepts in operating system memory management that together determine the physical memory usage for each process. Here’s an explanation of both algorithms and how to evaluate a page replacement algorithm.
Frame Allocation Algorithm
The frame allocation algorithm decides how many frames to give to each process. There are typically two main approaches:
- Fixed Allocation: Each process is allocated a fixed number of frames regardless of its actual requirements.
- Variable Allocation: The number of frames allocated to each process is adjusted dynamically based on actual needs. This can be achieved through global or local replacement policies:
- Global Replacement: All free frames form a shared pool from which any process can obtain or release frames.
- Local Replacement: Each process has its own fixed set of frames, and when it needs to replace a page, it must do so only within its own set of frames.
Page Replacement Algorithm
A page replacement algorithm determines which frame to replace when no free frames are available, aiming to minimize the page fault rate. Common page replacement algorithms include:
- FIFO (First-In, First-Out): Pages are replaced in the order they entered memory.
- LRU (Least Recently Used): The page that has not been used for the longest time is replaced.
- LFU (Least Frequently Used): The page that has been used the least often is replaced.
- Optimal Page Replacement: Theoretically optimal, this algorithm would choose the page that will not be used for the longest period in the future as the victim page, but it requires knowing the future, making it impractical.
To evaluate the effectiveness of a page replacement algorithm:
- Reference String: Run the algorithm on a specific string of memory references (containing just page numbers, not full addresses) and compute the number of page faults on that string.
- Belady’s Anomaly: Sometimes increasing the number of frames can lead to a higher page fault rate, a phenomenon known as Belady’s anomaly.
Note that repeated access to the same page does not cause a page fault because the page is already in memory. Evaluation results depend on the number of frames available; different frame counts can result in different page fault rates.
Thrashing
If a process does not have “enough” pages, the page-fault rate is very high. This means that the operating system frequently loads pages from disk into memory and then quickly needs to swap out these pages because they are being replaced by other pages that also urgently need memory. This phenomenon leads to low CPU utilization since most of the time is spent on page replacement rather than executing actual tasks. The operating system might misinterpret this situation as a need to increase the degree of multiprogramming (i.e., running more processes concurrently) to improve resource efficiency, but in practice, it can lead to decreased performance because adding more processes only exacerbates memory contention and page fault frequency.
Why Does Demand Paging Work?
Demand paging works effectively due to the principle of locality. The principle of locality suggests that programs tend to access a limited part of the address space rather than accessing the entire address space randomly. Specifically:
- Temporal Locality: If an item of information is referenced, it will tend to be referenced again soon.
- Spatial Locality: If a particular storage location is referenced, other locations nearby may also be referenced soon.
Because of this locality, even if only a portion of the pages is loaded into memory, most memory references still hit the pages in memory, thereby reducing the occurrence of page faults.
Why Does Thrashing Occur?
Thrashing occurs when the sum of the sizes of localities that processes are currently using exceeds the total physical memory available. As processes migrate from one locality to another, these localities might overlap, but more importantly, thrashing happens because there’s not enough memory for all the current working sets of the processes. Thrashing is characterized by an extremely high number of page faults where most CPU cycles are used for handling page faults instead of doing any useful work. This is because each process is constantly fighting for limited memory resources, swapping pages in and out incessantly.
How to Limit the Effects of Thrashing?
To mitigate the effects of thrashing, local or priority-based page replacement algorithms can be employed:
- Local Page Replacement Algorithms: Allow a process to replace only those frames allocated to it without affecting the pages of other processes. This prevents one process’s high page-fault rate from impacting the performance of the whole system.
- Priority-Based Page Replacement Strategies: Assign different priorities based on the importance of pages or the likelihood of them being accessed recently or in the near future. Pages with higher priorities are less likely to be replaced.
By applying these methods, the negative impact of thrashing on system performance can be somewhat alleviated.
Comments