Backend Interview Questions

Recently, I am applying for a backend developer summer internship and I have been asked a few questions were quite interesting. This post is a collection of backend interview questions which I have encountered. Hope it can help you when you are finding yourself in the same situation 🌟. Since I am applying positions based in China, I will discuss the questions both in Chinese and English.
最近,我正在寻找后端开发的暑期实习,被问了一些有趣的问题。这篇博客是我遇到的问题的汇总,希望能帮助到需要的人。因为我寻找的是大陆的岗位,所以在本文中会同时使用英文和中文。📚
Table of Contents 目录
- Language Based 语言基础
- What is Difference between malloc and new?
- Introducing the Standard Template Library (STL) in Cpp
- What is the Difference between insert / push and emplace When Using STL Container?
- What is the Difference of map and set in the Cpp STL?
- What is the Implementation Principle of Virtual Function in Cpp?
- How to Access Cpp Private Member Variables through Non-Standard Methods without Changing the Source Code?
- Database Based 数据库基础
- Operating System Based 操作系统基础
- Network Based 网络基础
- Intelligence Questions 智力题
Language Based 语言基础
What is Difference between malloc and new?
Tencent Interview Round 1 腾讯第一轮面试malloc and new are key mechanisms for dynamic memory allocation in C/C++, but they have significant differences in their underlying behaviors and usage scenarios. In terms of language, malloc is a function from the C standard library but can also be normally called in C++. It returns a void* pointer, requiring manual type specification. On the other hand, new is a C++ operator that automatically allocates memory based on type, returning a pointer with an explicitly known type. Here’s a simple example to create a pointer to an int:
int* p1 = (int*)malloc(sizeof(int)); // C style, return void*
int* p2 = new int; // Cpp style, return int*
From this example, it can also be seen that when using malloc, the user needs to explicitly specify the number of bytes, whereas new handles this automatically.
When the type is an object, using mallocand free only allocates and releases memory without invoking the object’s constructor or destructor, while new and delete do the opposite. At this point, new and delete will first call the constructor or destructor before allocating or releasing memory. When dealing with arrays, malloc requires manually calculating the number of bytes needed for the array, and free does not require specifying the byte count; new and delete[] ensure that the constructor and destructor of each element in the array are called.
In terms of error handling, malloc returns Null when allocation fails, thus requiring manual checking, whereas new throws an exception upon failure, eliminating the need for checking (though we can opt to use nothrow, in which case an exception will result in a return of nullptr).
int* p3 = (int*)malloc(10000000000LL); // Check Error
if (!p3) { /* Error Handling */ }
try {
int* p4 = new int[10000000000LL]; // Throw Exception
} catch (const std::bad_alloc& e) {
/* Error Handling */
}
int* p5 = new (std::nothrow) int[10000000000LL]; // Without Exception, return nullptr
if (!p5) { /* Error Handling */ }
Regarding overload mechanisms, malloc and free cannot be overloaded. However, the more modern new and delete operators can be overloaded to achieve highly customized memory allocation.
malloc 和 new 是 C/C++ 中用于动态内存分配的关键机制,但它们在底层行为和使用场景上有显著区别。 在语言方面,malloc 是C标准库的函数但是在Cpp也可以正常调用,返回的是 void* 需要手动指定类型。而 new 是 Cpp 运算符,可以根据类型自动分配内存,返回的指针类型明确。以下是一个简单的例子,创造 int 的指针。
从这个例子同时我们也可以看到,在使用 malloc 的时候,使用者需要显示的指定字节数,而 new 会自动完成。
当类型是对象时,使用 malloc 和 free 仅仅会分配和释放内存的时候而不会调用对象的构造函数和析构函数,而 new 和 delete 相反。注意这个时候 new 和 delete 会先调用构造函数或者析构函数,然后再分配和释放内存。当类型是数组的时候,malloc 需要手动指定计算数组所需要字节数,free 不必指定字节数量;new 和 delete[] 会确保调用数组中的每一个元素的构造函数和析构函数。
在错误处理方面,malloc 在无法分配的时候会返回 Null,因此需要手动检查,而 new 在无法分配的时候会抛出异常,不需要检查 (当然我们也可以选择使用 nothrow,这时候发生异常会返回nullptr)。
在重载机制上,malloc 以及 free 是不能进行重载的。而更现代化的 new 和 delete 是可以进行重载来实现高度自定义的内存分配。
Introducing the Standard Template Library (STL) in Cpp
Tencent Interview Round 2 腾讯第二轮面试The STL (Standard Template Library) is an essential part of the C++ Standard Library. It’s not only a reusable component library but also embodies a software architecture encompassing data structures and algorithms. Its core design philosophy centers around the concept of “separation of data and operations”, achieving highly modularized and generic programming through the collaboration of six major components. Here’s a summary of these components:
| Component | Function | Examples |
|---|---|---|
| Containers | Store and manage data | vector, list, map |
| Algorithms | Operate on data (sorting, searching, etc.) | sort, find, transform |
| Iterators | Bridge between containers and algorithms, providing a unified interface for accessing elements | iterator, reverse_iterator |
| Functors | Enable functions to have object-like properties, used for customizing algorithm behavior | less |
| Adapters | Encapsulate existing components, altering interfaces or functionalities | stack, queue, priority_queue |
| Allocators | Manage memory allocation and deallocation | allocator |
Containers are structures designed for storing and managing data, encapsulating underlying data structures to some extent. They provide a unified data access interface (through iterators) and support automatic memory management (such as dynamic expansion in vector). Containers are categorized into sequential containers (vector, list, array, etc.), associative containers (map, set, etc.), and unordered associative containers introduced in C++11 (unordered_set, unordered_map, etc.).
The algorithm component is separated from the container component; it operates on the data within containers (like sorting, searching, traversing) without depending on specific container types, using iterators instead. These operations are non-intrusive, meaning they modify the data within containers without altering the container structure itself. Common usages include:
vector<int> v = {10, 9, 8, 7, 6, 5, 4, 3, 2, 1};
sort(v.begin(), v.end());
auto it = find(v.begin(), v.end(), 5);
vector<int> new_v = transform(v.begin(), v.end(), [](int x) { return x * 2; });
Iterators offer a unified interface for accessing container elements, abstracting away the differences in underlying implementations. By functionality, they can be classified into forward iterators (forward_list), bidirectional iterators (map, list), and random access iterators (vector, set), among others.
Functors are class objects that overload the operator(), allowing them to be invoked like functions. They are typically used for customizing algorithm behaviors (such as sorting rules, conditional judgments). Common functors in the standard library include:
- Arithmetic operations:
plus<T>,minus<T> - Relational comparisons:
less<T>,greater<T> - Logical operations:
logical_and<T>,logical_not<T>
Adapters primarily function to encapsulate existing components, changing their interfaces or functionalities to adapt them for use in different scenarios or to provide a more uniform interface. Common adapters include:
- Container adapters:
stack,queue,priority_queue, which are implemented based on deque or vector. - Iterator adapters:
reverse_iterator, enabling reverse traversal of containers. - Function adapters:
bind,not1,mem_fn, wrapping functions into objects for use in algorithms. Note that since C++11, these adapters have largely been replaced by lambda expressions.
Allocators are used for managing memory allocation and deallocation for containers, implementing memory control and optimization. The default allocator is std::allocator<T>. Custom allocators can also be defined by overloading allocate() and deallocate(), facilitating advanced features such as memory pools.
STL是Cpp标准库的重要组成部分,不仅是一个可复用的组件库,也是一个包含了数据结构与算法的软件架构。其核心设计理念是 “数据与操作分离”,通过六大组件的协作,实现了高度模块化和泛型编程。我们可以对这些组件进行以下总结。
容器是一种存储和管理数据的结构,其也在一定程度上封装了底层数据结构。其提供统一的数据访问接口(通过迭代器),也支持自动管理内存(如 vector 的动态扩容)。在分类上分为顺序容器(vector, list, array 等),关联容器(map, set 等),以及Cpp11后的顺序关联容器(unordered_set, unordered_map等)
算法组件和容器组件分离,其对容器中的数据进行操作,如排序、查找、遍历等而不用依赖具体容器类型,通过迭代器操作。其操作也是非侵入式的,仅仅是对容器中的数据进行改变而不修改容器的结构。一些常见的用法如下。
迭代器提供了访问容器元素的统一接口,屏蔽底层实现差异。按功能可以分为前向迭代器(forward_list),双向迭代器(map, list),随机迭代器(vector, set)等。
仿函数是一种可以重载 operator() 的类对象,可像函数一样调用。它通常用于定制算法行为(如排序规则、条件判断)。在标准库中有以下常用的仿函数:
- 算术运算:
plus<T>,minus<T> - 关系比较:
less<T>,greater<T> - 逻辑运算:
logical_and<T>,logical_not<T>
配接器的主要功能是对现有组件进行封装,改变其接口或功能。这样可以使得组件能够在不同的情况下使用,或者是提供了一个更加统一的接口。常见的配接器包括:
- 容器配接器:
stack,queue,priority_queue,这些配接器都是基于 deque 或 vector 实现的。 - 迭代器配接器:
reverse_iterator,这个配接器可以实现反向遍历容器。 - 函数配接器:
bind,not1,mem_fn,这些配接器可以将函数包装成一个对象,从而能够在算法中使用。注意 Cpp11 之后,这些配接器多被 Lambda 表达式所取代。
空间配置器用于管理容器的内存分配与释放,实现内存控制与优化。默认配置器:std::allocator<T>。也可以自定义配置器,重载 allocate() 和 deallocate(),实现内存池等高级功能。
What is the Difference between insert / push and emplace When Using STL Container?
Taotian Group Written Test 淘天集团笔试In the Cpp Standard Template Library (STL), the core difference between insert and emplace lies in the timing and manner of object construction. The insert operation requires the caller to provide a fully constructed object as an argument, meaning that this object must be constructed at the call site (potentially involving the creation of temporary objects) before being taken into management by the container through copy or move semantics. While this pattern can be optimized to a move operation when passing rvalues, there is still unavoidable construction overhead for lvalues or scenarios requiring in-place construction. In contrast, emplace uses perfect forwarding technology to directly capture the construction parameters and construct the object in place within the container’s memory space, completely eliminating the generation of temporary objects. This difference is particularly critical for types with high construction costs (such as classes involving dynamic memory allocation) or types that are neither copyable nor movable, where emplace is not only a performance optimization but sometimes the only viable solution.
From the perspective of implementation mechanisms, emplace methods leverage variadic templates and reference collapsing rules to pass any number and type of construction parameters losslessly to the constructor of elements. This design ensures that emplace introduces no additional type conversions or temporary objects during the parameter passing stage, whereas insert, due to limitations imposed by its interface design, requires its arguments to be of the container’s element type or convertible to it. For example, in std::map<std::string, int>, emplace("key", 42) can directly pass a string literal and an integer, while the equivalent insert operation would require explicitly constructing a std::pair object. This syntactic simplicity further highlights the advantages of emplace in practical coding.
Although emplace is generally superior in most scenarios, its behavior may be counterintuitive in certain contexts. Since parameters are directly used for constructor calls, implicit type conversions occur during the element construction phase rather than the parameter passing phase, which might affect the outcome of overload resolution. Additionally, for containers with special semantics (like the specialization of std::vector<bool>) or when constructors include extra logic (such as parameter validation), emplace may exhibit different exception safety guarantees compared to insert. Therefore, caution should be exercised when strong exception safety guarantees are required or when dealing with specialized versions of containers. Overall, understanding the underlying mechanism differences between the two allows for making informed choices based on object lifecycle, construction cost, and exception safety requirements in actual development.
在C++ STL中,insert和emplace的核心区别在于对象构造的时机和方式。insert操作要求调用者提供一个已构造的完整对象作为参数,这意味着在调用点必须先构造该对象(可能伴随临时对象的创建),然后容器内部通过拷贝或移动语义将其纳入管理。这种模式在传递右值时可以优化为移动操作,但对于左值或需要就地构造的场景仍存在不可避免的构造开销。相比之下,emplace通过完美转发(perfect forwarding)技术直接捕获构造参数,在容器内部的内存空间中原地构造对象,完全消除了临时对象的产生。这种差异在构造成本高的类型(如包含动态内存分配的类)或不可拷贝/移动的类型时尤为关键,此时emplace不仅是性能优化手段,甚至是唯一可行的方案。
从实现机制来看,emplace系列方法利用了变参模板和引用折叠规则,能够将任意数量和类型的构造参数无损地传递给元素的构造函数。这种设计使得emplace在参数传递阶段不会引入任何额外的类型转换或临时对象,而insert由于接口设计限制,其参数必须是容器元素类型或可转换为该类型的对象。例如,在std::map<std::string, int>中,emplace("key", 42)可以直接传递字符串字面量和整数,而等效的insert操作则需要显式构造std::pair对象。这种语法层面的简洁性进一步强化了emplace在实际编码中的优势。
虽然emplace在大多数情况下更优,但其行为在某些场景下可能违反直觉。由于参数直接用于构造函数调用,隐式类型转换会发生在元素构造阶段而非参数传递阶段,这可能影响重载决议的结果。此外,对于具有特殊语义的容器(如std::vector<bool>特化版本),或当构造函数包含额外逻辑(如参数验证)时,emplace可能表现出与insert不同的异常安全保证。因此,在需要强异常安全保证或处理容器特化版本时,仍需谨慎选择。总体而言,理解两者底层机制的差异,才能在实际开发中根据对象生命周期、构造成本及异常安全需求做出合理选择。
What is the Difference of map and set in the Cpp STL?
Tencent Interview Round 3 腾讯第三轮面试The set and map containers in the STL share a deep common origin but also exhibit critical differences. We can analyze them thoroughly from four dimensions: data structure, memory organization, operational characteristics, and use cases.
From the perspective of the underlying data structure, both typically use a red-black tree as their foundational implementation. This is a self-balancing binary search tree that guarantees a worst-case time complexity of $O(\log n)$. This choice stems from the strict ordering requirements of associative containers and the excellent balance of red-black trees in insertion, deletion, and lookup operations.
In terms of memory organization, a set is essentially a collection of keys, where its tree nodes only contain key values and necessary tree structure pointers (left child, right child, parent node pointers, and red-black tree color markers). In contrast, a map needs to store key-value pairs, with its node structure containing std::pair<const Key, Value>. This makes the size of a map node generally larger than that of a set by sizeof(Value) bytes.
This difference in memory layout triggers a series of chain effects: First, the memory footprint of a map is significantly higher than that of a set, especially when storing large objects. Second, because set nodes are smaller, they exhibit better cache locality during traversal. Additionally, map requires handling more complex construction and destruction logic, as its value part may involve resource management. Notably, modern C++ standards require strong exception safety guarantees for container nodes in case of insertion failure, which imposes higher demands on the implementation of map.
In terms of operational characteristics, although both have the same theoretical time complexity for basic operations (insert, erase, find, etc.), in actual execution, set often demonstrates better performance due to differences in memory access patterns. Specifically:
- Lookup operations in
setmay be 5-15% faster due to smaller nodes leading to higher cache hit rates. - Insertion operations in
mapare slower because constructingpairobjects is required. - Traversal operations in
setare typically 10-30% faster, benefiting from better spatial locality.
Regarding iterators, dereferencing a set iterator yields a const Key&, emphasizing the immutability of keys; whereas a map iterator returns a pair<const Key, Value>&, allowing modification of the value while keeping the key const. This design ensures the key invariant of associative containers: the ordering relationship of elements will not change unexpectedly.
From the perspective of use cases, set is suitable for scenarios requiring the maintenance of a unique, ordered collection, such as whitelist checks or leaderboards. On the other hand, map is ideal for key-value mapping needs, such as configuration storage or dictionaries. The node operations introduced in C++17 (extract/insert) enable efficient mutual conversion between the two, such as migrating set nodes into a map. This operation involves only pointer adjustments without data copying.
In special cases, developers may need to consider the following:
- When the value size is very large, consider using
setwith parallel arrays or pointer storage to optimize. - After C++11,
unordered_setandunordered_mapmay provide better average performance. - In multithreaded environments, both require external synchronization mechanisms.
Modern compilers’ optimization capabilities have significantly narrowed the performance gap between the two. However, in extreme performance-sensitive scenarios, understanding these low-level differences remains crucial. The choice should be based on semantic requirements (whether associated values are needed) rather than minor performance differences—code readability and maintainability are usually more important than micro-optimizations.
STL中的set和map容器在实现上既有深刻的同源性又存在关键性差异,我们可以从数据结构、内存组织、操作特性和使用场景四个维度进行深入剖析。
从底层数据结构来看,两者通常都采用红黑树作为基础实现,这是一种自平衡的二叉搜索树,能够保证最坏情况下$O(log n)$的时间复杂度。这种选择源于关联容器对有序性的严格要求,以及红黑树在插入、删除和查找操作上的良好平衡性。
在内存组织方面,set本质上是一个键的集合,其树节点仅包含键值和必要的树结构指针(左子树、右子树、父节点指针以及红黑树颜色标记)。而map则需要存储键值对,其节点结构包含std::pair<const Key, Value>,这使得map的节点尺寸通常比set大sizeof(Value)字节。
这种内存布局差异带来了一系列连锁效应:首先,map的内存占用明显高于set,特别是在存储大对象时;其次,set由于节点更小,在遍历时具有更好的缓存局部性;再者,map需要处理更复杂的构造和析构逻辑,因为其value部分可能涉及资源管理。值得注意的是,现代C++标准要求容器的节点在插入失败时保证强异常安全,这对map的实现提出了更高要求。
在操作特性上,虽然两者的基本操作(insert、erase、find等)都具有相同的理论时间复杂度,但在实际运行中,由于内存访问模式的差异,set通常能表现出更好的性能。具体来说:
- 查找操作在set中可能快5-15%,因为更小的节点带来更高的缓存命中率
- 插入操作在map中更耗时,因为需要构造pair对象
- 遍历操作在set中通常快10-30%,受益于更好的空间局部性
迭代器方面,set的迭代器解引用得到const Key&,强调键的不可变性;map迭代器则返回pair<const Key, Value>&,允许修改value但保持key的const特性。这种设计保证了关联容器的关键不变量:元素的排序关系不会意外改变。
从使用场景来看,set适用于需要维护唯一有序集合的场景,如白名单检查、排行榜等;map则适合键值映射需求,如配置存储、字典等。C++17引入的节点操作(extract/insert)使得两者可以高效互转,例如将set的节点迁移到map中,这种操作仅涉及指针调整而不需要数据拷贝。
在特殊情况下,开发者可能需要注意:
- 当value体积很大时,考虑使用set+并行数组或指针存储来优化
- 在C++11后,unordered_set和unordered_map可能提供更好的平均性能
- 多线程环境下,两者都需要外部同步机制
现代编译器的优化能力已经大大缩小了两者的性能差距,但在极端性能敏感的场景下,理解这些底层差异仍然至关重要。选择时应当基于语义需求(是否需要关联值)而非微小的性能差异,代码的可读性和维护性通常比微优化更重要。
What is the Implementation Principle of Virtual Function in Cpp?
Tencent Interview Round 2 腾讯第二轮面试In C++, virtual functions are a crucial mechanism for achieving polymorphism, allowing derived classes to override methods from a base class and ensuring the correct function is called at runtime based on the actual object type. First, let’s discuss the basic concepts of virtual functions. In C++, if a member function is declared as virtual in a base class, then even if we call that function through a base class pointer or reference, the overridden version in the derived class will be invoked instead of the base class version. This effect of dynamic binding is achieved through the virtual function table (vtable) and the virtual pointer (vptr).
The virtual function table is a table storing addresses of virtual functions. Each class with virtual functions has a unique vtable. It is essentially an array of pointers, with each element pointing to the implementation of a virtual function for that class. The vtable is created at compile time and used during runtime for function calls.
The virtual pointer is a hidden pointer within each object of a class that contains virtual functions, pointing to the object’s class’s virtual function table. When an object of such a class is created, its constructor automatically sets the vptr to point to the vtable of that class. Because the vptr is stored inside the object, different objects can have different vtables, enabling dynamic polymorphism. Since the vptr occupies additional storage space in the object (typically 8 bytes), objects of classes containing virtual functions take up slightly more memory than ordinary class objects.
Additionally, it is worth noting that if a function is a pure virtual function, which lacks a concrete implementation, subclasses must override it; otherwise, those subclasses also become abstract classes and cannot be instantiated. An abstract class refers to a class that contains at least one pure virtual function and cannot directly create objects.
在 Cpp 中,虚函数是实现多态的重要机制,它允许派生类覆盖基类的方法,并且在运行时根据对象的实际类型调用正确的函数。首先我们来谈论一下虚函数的基本概念,在 Cpp 中如果一个成员函数在基类中声明为 virtual 那么即使我们通过基类指针或引用调用该函数,也会调用派生类中重写的版本,而不是基类版本。这种动态绑定的效果就是通过虚函数表和虚指针实现的。
虚函数表是一个存储虚函数地址的表,每个类(如果有虚函数)都有一个唯一的虚表。它是一个指针数组,每个元素指向该类的虚函数实现。虚表在编译时创建,在程序运行时用于函数调用。
虚指针是每个含有虚函数的类的对象内部的一个隐藏指针,指向该对象所属的类的虚函数表。当一个类对象被创建时,构造函数会自动设置虚指针指向该类的虚函数表。由于虚指针存储在对象内部,因此不同对象可以有不同的虚函数表,从而实现动态多态。由于虚指针占据了对象的额外存储空间(通常 8 字节),因此包含虚函数的类的对象会比普通类对象多占用一点内存。
另外值得关注是如果是纯虚函数,其没有具体实现,子类必须重写,否则该子类也是抽象类,无法实例化。而抽象类指的是至少包含一个纯虚函数的类,这样的类不能直接创建对象。
How to Access Cpp Private Member Variables through Non-Standard Methods without Changing the Source Code?
Tencent Interview Round 3 腾讯面试第三轮Accessing a class’s private member variables in C++ is a fundamental breach of the object-oriented encapsulation principle, requiring a deep understanding of underlying language mechanisms and accepting the associated risks. From a technical implementation perspective, such operations essentially circumvent the compiler’s access control mechanisms to directly manipulate the object’s memory representation. The pointer offset method is the closest to low-level manipulation, relying on characteristics of an object’s memory layout that are not guaranteed by the C++ standard. In simple cases, one can use reinterpret_cast to convert an object pointer to a char* type pointer and then add a calculated member offset to access private data. This approach might work for classes with single inheritance and no virtual functions, but becomes extremely complex and unreliable when dealing with multiple inheritance, virtual functions, or compiler optimizations. More critically, the C++ standard explicitly defines accessing non-public members via pointer arithmetic as undefined behavior, meaning different compilers or even different versions of the same compiler may produce inconsistent results.
Using a preprocessor macro like #define private public is a direct violation of C++ syntax rules, altering class access control properties through textual replacement before compilation. Although this method seems straightforward, it introduces serious semantic issues. Modern C++ compilers may produce unpredictable outcomes when handling such replacements, especially when involving advanced features like template metaprogramming or SFINAE. Moreover, this modification affects all translation units including the header file, potentially leading to ODR (One Definition Rule) violations and causing hard-to-diagnose errors during the linking phase. The debugger intervention approach involves directly modifying data in the process’s memory space at runtime, which, while bypassing all compiler protections, requires developers to have an extremely precise grasp of the program’s memory layout and does not yield reusable code solutions.
From a software engineering standpoint, these techniques suffer from fundamental flaws. They break class encapsulation, making code maintenance difficult and rendering static type checking and other compiler safety mechanisms ineffective. Even more seriously, these methods rely on implementation details rather than standard specifications, meaning any compiler upgrade or architecture change could render existing code unusable. In practice, scenarios where there is a genuine need to access private members often indicate design flaws, and a more reasonable solution would be to refactor the code structure—by using friend declarations, providing controlled access interfaces, or reconsidering relationships between classes to meet requirements. In special cases where source code cannot be modified (such as debugging third-party libraries), one should prioritize using standard tools like debugging symbols over these destructive access methods. The value of these non-standard methods is mainly confined to specific areas such as low-level development, reverse engineering, or emergency debugging, and they should be strictly avoided in regular software development.
在Cpp中强行访问类的private成员变量是对面向对象封装原则的根本性突破,需要深入理解语言底层机制并承担相应的风险。从技术实现角度来看,这类操作本质上都是通过某种方式绕过编译器的访问控制机制,直接操作对象的内存表示。指针偏移法是最接近底层的方式,它依赖于Cpp标准并不保证的对象内存布局特性,在简单情况下可以通过reinterpret_cast将对象指针转换为char*类型指针后加上计算得到的成员偏移量来访问``private`数据。这种方法在单继承且不含虚函数的类结构中可能有效,但一旦涉及多继承、虚函数或编译器优化,偏移量计算就会变得极其复杂且不可靠。更关键的是,Cpp标准明确将这类通过指针算术访问非公有成员的行为定义为未定义行为,意味着不同编译器甚至同一编译器的不同版本都可能产生不一致的结果。
#define private public这种预处理宏替换的方法则是对Cpp语法规则的直接破坏,它在编译前阶段通过文本替换改变类的访问控制属性。这种方法虽然看似简单直接,但实际上会带来严重的语义问题。现代Cpp编译器在处理这类替换时可能会产生难以预料的后果,特别是在涉及模板元编程或SFINAE等高级特性时。此外,这种修改会影响到所有包含该头文件的编译单元,可能引发ODR(单一定义规则)违规,导致链接阶段出现难以诊断的错误。调试器干预的方式则是在运行时直接修改进程内存空间中的数据,这种方法虽然可以绕过编译器的所有保护措施,但要求开发者对程序的内存布局有极其精确的把握,且无法形成可重复使用的代码解决方案。
从软件工程的角度来看,这些技术手段都存在根本性缺陷。它们破坏了类的封装性,使得代码维护变得困难,也使得静态类型检查等编译器保障机制失效。更严重的是,这些方法都建立在实现细节而非标准规范之上,任何编译器升级或架构变更都可能导致原有代码失效。在实践中,真正需要访问private成员的场景往往反映了设计上的缺陷,更合理的解决方案应该是重构代码结构,通过友元声明、提供受控的访问接口或重新考虑类之间的关系来满足需求。在确实无法修改源代码的特殊情况下(如调试第三方库),也应当优先考虑使用调试符号等标准工具,而非依赖这些破坏性的访问方式。这些非标准方法的价值主要局限在特定领域的底层开发、逆向工程或紧急调试等特殊场景,在常规软件开发中应当严格避免使用。
Database Based 数据库基础
Comparisons between B+ Tree and B Tree
Tencent Interview Round 2 腾讯第二轮面试In practical applications, the B+ tree is more suitable for use in database indexing due to its stable read and write performance and the characteristic of having an ordered linked list at the leaf nodes. On the other hand, B-trees are sometimes used in scenarios that require frequent data updates. From the perspective of similarities, both are multiway balanced search trees with a highly balanced nature. Nodes can have multiple child entries, not just two, making them multi-branch. In these trees, each node’s keys are sorted, and the keys within a node separate the ranges of its child nodes. The time complexity for search, insertion, and deletion operations is $O(\log n)$ for both.
Although their external structures are similar, they differ in where they store data. In a B-tree, each node contains both keys and data, so data can be found in non-leaf nodes, making data updates simpler. In contrast, in a B+ tree, all data is retained in the leaf nodes, which are typically connected in a linked list format, while non-leaf nodes only store key information. Additionally, leaf nodes are linked together via pointers to form a linked list, facilitating full-range scans and sequential access. These differences in data storage lead to variations in search efficiency and application scenarios.
在实际应用中,B+树由于其读写性能稳定和叶子节点的顺序链表特性,使得它更适合用于数据库索引。而B树则有时候用于那些需要频繁对数据进行更新的场景。从相似性的角度,他们都是都是多路平衡查找树,有高度平衡的性质。节点可以拥有多个子项,不仅是两个,因此是多叉的。树中的每个节点都是按照键值有序排列的,并且每个节点中的键分隔了其子节点的范围。搜索、插入、删除操作的时间复杂度都是$O(log n)$。
虽然外部结构是类似的,当时存储数据的位置有所不同。在B树中,每个节点都包含键和数据,因此,数据可以在非叶子节点找到,其在更新数据的时候也会更简单;但是在B+树中,所有的数据都保留在叶子节点中,并且通常以链表的方式进行连接,非叶子节点只存储键信息,且叶子节点通过指针串联成一个链表,方便全范围扫描和顺序访问。存储数据上的差异也带来了搜索效率上和应用场景下的差异。
What is Transaction? What is ACID?
Tencent Interview Round 2 腾讯第二轮面试In database systems, a transaction is a logical unit of atomic operations designed to ensure data consistency and integrity. It manages database operations by satisfying the ACID properties (Atomicity, Consistency, Isolation, Durability), ensuring that data remains in a correct state even in cases of system failures or concurrent access. Here’s a summary of the characteristics of transactions:
- All operations within a transaction either succeed and are committed entirely, or fail and are rolled back completely. For instance, in a bank transfer, both debiting and crediting must be completed simultaneously or canceled altogether, with no intermediate states. This is known as atomicity, which represents the smallest indivisible unit logically.
- Consistency means that after executing a transaction, the database must transition from one valid state to another. For example, during a transfer, the total amount in accounts should remain consistent, adhering to business rules.
- The isolation of transactions ensures that operations under concurrent scenarios do not interfere with each other, as if they were executed serially. Different isolation levels (such as Read Committed, Repeatable Read) are achieved through locking mechanisms or multi-version control, preventing issues like dirty reads, non-repeatable reads, etc.
- Durability of transactions refers to the fact that once a transaction has been executed, the data in the database will not be lost, even in the event of system failures or crashes. This is realized through logging and log replay for durability.
In practice, a bank system’s transfer operation might involve multiple tables, such as account tables and transfer record tables. Simultaneously, it needs to complete both debiting and crediting without interference from different transfer operations involving different accounts. This scenario serves as a classic example illustrating the characteristics of transactions.
Regarding the lifecycle of transactions, it can generally be divided into several phases:
- Active: The transaction is performing operations.
- Partially Committed: Operations have been executed but not yet committed.
- Committed: Successfully completed, changes become permanent.
- Failed: Cannot continue execution and needs to be rolled back.
- Aborted: After rollback, the database returns to its state before the transaction began.
Another important trade-off concerning transactions occurs between isolation levels and concurrency issues. Here are some potential concurrency problems between transactions:
- Dirty Reads: Reading uncommitted data from other transactions.
- Non-repeatable Reads: The same data read twice within the same transaction yields different results.
- Phantom Reads: The number of rows returned by the same query condition changes due to inserts/deletes by other transactions.
To avoid these concurrency issues, trade-offs need to be made regarding the isolation level of transactions. Generally, the higher the isolation level, the fewer concurrency problems occur, but this also leads to poorer transaction performance. Transaction isolation levels can be categorized as follows:
- Read Uncommitted: Offers the best concurrency performance for transactions but may lead to dirty reads.
- Read Committed: Avoids dirty reads but may still result in non-repeatable reads.
- Repeatable Read: Ensures that multiple reads within the same transaction yield consistent results (default in MySQL).
- Serializable: Provides full isolation, implemented through table locking, resulting in the lowest performance.
To achieve various transaction characteristics, the following mechanisms can be utilized:
- Logging: Records transaction operations (such as Redo/Undo logs) for fault recovery.
- Locking: Controls concurrent access (e.g., row locks, table locks).
- Multi-Version Concurrency Control (MVCC): Implements non-blocking reads via data snapshots (e.g.,
PostgreSQL,MySQL,InnoDB).
Recommended practices include using short transactions whenever possible to reduce lock contention and improve concurrent performance; reasonably selecting isolation levels to balance consistency and performance; and paying attention to exception handling to avoid situations of partial commitment.
数据库系统中的事务是一组原子性操作的逻辑单元,用于确保数据的一致性和完整性。它通过满足ACID特性(原子性、一致性、隔离性、持久性)来管理对数据库的操作,使得即使在系统故障或并发访问的情况下,数据仍能保持正确状态。关于事务的特性,我们可以进行以下总结:
- 事务中的所有操作要么全部成功提交,要么全部失败回滚。例如,银行转账中扣款和加款必须同时完成或同时取消,不存在中间状态。这就是所谓的原子性,其是逻辑上不可再分化的最小单元。
- 一致性是指事务执行后,数据库必须从一个有效状态转换到另一个有效状态。例如,转账前后账户总金额需保持一致,符合业务规则。
- 事务的隔离性确保了,数据库在并发场景下的操作不会互相干扰,如同串行执行。通过锁机制或多版本控制实现不同隔离级别(如读已提交、可重复读),避免脏读、不可重复读等问题。
- 事务的持久性是指事务执行后,数据库中的数据不会丢失,即使在系统故障或系统崩溃时。通过日志记录和日志回放实现事务的持久性。
在实践中,银行系统的转账操作可能会涉及多个表,如账户表、转账记录表等。同时转账操作也需要同时完成扣款和加款。并且不同的转账操作可能会涉及不同的账户,因此需要避免相互干扰。这个场景是说明事务特性的一个经典的例子。
关于事务的生命周期,可以大概分成以下几个阶段:
- 活动状态(Active):事务正在执行操作。
- 部分提交(Partially Committed):操作执行完成,但尚未提交。
- 提交(Committed):成功完成,修改永久生效。
- 失败(Failed):无法继续执行,需回滚。
- 中止(Aborted):回滚后,数据库恢复到事务开始前的状态。
而关于事务的另外一个比较重要的权衡发生在 隔离级别 和 并发问题 上。我们先来谈谈事务之间可能会存在以下并发问题:
- 脏读:读取到其他事务未提交的数据。
- 不可重复读:同一事务内两次读取同一数据结果不同。
- 幻读:同一查询条件返回的行数因其他事务插入/删除而改变。
为了避免这些并发问题,需要在事务的隔离级别上做出权衡。一般来说隔离级别越高,并发问题越少,但是事务的性能也会越差。事务的隔离级别可以分为以下几个级别:
- 读未提交:此时事务的并发性能最好,但可能会导致脏读。
- 读已提交:避免脏读,但可能不可重复读。
- 可重复读:保证同一事务内多次读取结果一致(MySQL默认)。
- 可串行化:完全隔离,通过锁表实现,性能最低。
为了实现事务的各个特性,可以通过以下机制:
- 日志:记录事务操作(如Redo/Undo日志),用于故障恢复。
- 锁:控制并发访问(如行锁、表锁)。
- 多版本并发控制:通过数据快照实现非阻塞读(如
PostgreSQL,MySQL,InnoDB)。
以上,推荐的实践方式是尽可能使用短事务,来减少锁竞争,提升并发性能;同时合理选择隔离级别,权衡一致性与性能;也需要关心捕获异常的处理,避免部分提交的情况。
Operating System Based 操作系统基础
Introducing the Task Scheduling Algorithms. What is the difference of it in Linux and Windows?
Tencent Interview Round 2 腾讯第二轮面试The task scheduling algorithm of an operating system is a core mechanism for managing CPU resource allocation, primarily used to determine the execution order of multiple processes/threads. Different systems adopt various scheduling strategies based on their design goals (such as real-time performance, fairness, throughput). Here are brief introductions to some simple task scheduling algorithms:
First-Come, First-Served (FCFS) is a straightforward task scheduling algorithm that allocates the CPU according to the order in which processes arrive at the ready queue. It features simplicity and fairness but can lead to the “convoy effect,” where shorter jobs are blocked by longer ones.
Shortest Job Next (SJN) schedules processes based on their estimated run time, giving priority to those with the shortest expected runtime. This algorithm optimizes average waiting time but requires prior knowledge of job durations and is unfriendly to long jobs.
Round Robin (RR) assigns each process a fixed time slice (e.g., 10ms), after which the process must requeue. This approach emphasizes strong fairness and is suitable for interactive systems, though frequent context switching may reduce efficiency.
Priority Scheduling determines the scheduling order based on the priority of processes, which can be statically or dynamically adjusted. A downside of this method is that low-priority processes might suffer from “starvation.”
Multilevel Feedback Queue is an algorithm designed to balance response time and throughput by placing processes into multiple queues based on their priority levels, allowing dynamic promotion or demotion between queues. This algorithm is commonly used in actual systems like Windows.
As for Linux, its scheduler has undergone several evolutions, with the current mainstream being the Completely Fair Scheduler (CFS), which emphasizes fairness and throughput. It performs excellently in server environments and high-concurrency scenarios, especially in multi-core settings, although it may not respond as swiftly to interactive tasks as Windows does.
操作系统的任务调度算法是管理CPU资源分配的核心机制,主要用于决定多个进程/线程的执行顺序。不同系统根据设计目标(如实时性、公平性、吞吐量)采用不同的调度策略。简单的任务调度算法分别为:
先来先服务是一种简单的任务调度算法,根据进程到达就绪队列的顺序分配CPU。其特点是简单、公平,但可能导致“长作业阻塞短作业”。
短作业优先则是根据作业的预计运行时间来确定调度顺序的算法,优先执行预计运行时间最短的进程。该算法可以使得平均等待时间最优,但需要预知作业时间,对长作业不友好。
轮转调度则是每个进程分配固定时间片(如10ms),时间片用完则重新排队的算法。该算法的特点是公平性强,适合交互式系统,但频繁上下文切换可能降低效率。
优先级调度是根据进程的优先级来确定调度顺序的算法,优先级可以静态或动态调整。该算法的问题是低优先级进程可能“饿死”。
多级反馈队列是一种综合权衡响应时间和吞吐量的算法,将进程按优先级分到多个队列,队列间可动态升降级。实际系统(如Windows)常用该算法。
而Linux的调度器经过多次演进,目前主流是完全公平调度器,强调公平性和吞吐量。其适合服务器和高并发场景,尤其在多核环境下表现优异,但对交互式任务的响应略逊于Windows。
What is the Principle of Process Communication Using Pipes?
Tencent Interview Round 1 腾讯第一轮面试A process is the basic unit for operating system resource allocation, with each process having its own independent address space. Therefore, inter-process communication requires mechanisms provided by the operating system to be implemented, such as: pipes, message queues, shared memory, signals, and sockets. The essence of these communication methods is that the kernel acts as an intermediary, setting aside a region in kernel space for processes to exchange data. There are some core issues in process communication, namely:
- Data isolation: Processes have independent address spaces and cannot directly access each other’s memory.
- Synchronization and mutual exclusion: When multiple processes access shared resources simultaneously, competition conditions must be avoided.
- Performance and efficiency: Different communication methods vary greatly in speed and resource consumption.
Additionally, let’s mention the issue of communication between threads. Threads within the same process share the address space and resources of the process. Therefore, thread communication can be directly achieved through shared memory without kernel intervention. However, attention should be paid to shared data issues and synchronization/mutual exclusion problems.
Pipes mentioned in the question are a half-duplex communication mechanism where data flows in one direction at a time. They are implemented based on a kernel buffer, with both parties communicating through file descriptors to read and write data.
Half-duplex: Information transmission is bidirectional; however, at any given moment, only one party can transmit data while the other receives.
An anonymous pipe is the simplest form of a pipe, commonly used for communication between related processes (such as parent-child processes). Generally, the usage process of an anonymous pipe is as follows:
- First, perform a
pipe(int pipefd[2])system call to create an anonymous pipe.pipefd[0]is used for reading, andpipefd[1]for writing. It is a circular buffer in the kernel, with a default size of 64KB (which may vary depending on the operating system). - During data flow, data is written into the circular buffer via
pipefd[1]and read from and removed from the circular buffer viapipefd[0]. If the pipe is empty, the read operation will block until data is written. If the pipe is full, the write operation will block until data is read. - When all write ends are closed, the read end will read an end-of-file marker. When all read ends are closed, the write end will receive a
SIGPIPEsignal.
It should be noted that although anonymous pipes can facilitate bidirectional data flow, they are generally used for unidirectional data flow in practice. The following code demonstrates a simple example of using an anonymous pipe:
#include <string.h>
int main() {
int pipefd[2];
pid_t pid;
char buf[1024];
// Create Pipe
if (pipe(pipefd) == -1) {
perror("pipe");
return 1;
}
// Create Child Process
pid = fork();
if (pid < 0) {
perror("fork");
return 1;
}
// Child Process
if (pid == 0) {
close(pipefd[1]);
read(pipefd[0], buf, sizeof(buf));
printf("Child received: %s\n", buf);
close(pipefd[0]);
}
// Father Process
else {
close(pipefd[0]);
const char *msg = "Hello, child!";
write(pipefd[1], msg, strlen(msg) + 1);
close(pipefd[1]);
}
return 0;
}
If we consider using pipes or persistent information channels between any two processes, then we would need a named pipe. A named pipe is a special file that allows communication between unrelated processes. It is identified by a pathname in the filesystem. Its implementation process is almost identical to that of an anonymous pipe, except there are some differences in initializing the pipe and opening the pipe:
- Initializing the pipe requires using the
mkfifocommand or performing amkfifo()system call. - Opening the pipe file uses the
open()system call, with the read end using theO_RDONLYflag, the write end using theO_WRONLYflag, or either using theO_RDWRflag.
First, you can execute the mkfifo test_fifo command in the command line to create a named pipe file called test_fifo. Next, you can use the open function to open this file and then perform data read/write operations. For example, in one program, you might write data like this:
#include <stdio.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <unistd.h>
#include <string.h>
int main() {
int fd;
const char *fifo = "test_fifo";
const char *msg = "Hello, FIFO!";
fd = open(fifo, O_WRONLY);
write(fd, msg, strlen(msg) + 1);
close(fd);
return 0;
}
In another program, you could read the data like this:
#include <stdio.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <unistd.h>
int main() {
int fd;
char buf[1024];
const char *fifo = "myfifo";
fd = open(fifo, O_RDONLY);
read(fd, buf, sizeof(buf));
printf("Received: %s\n", buf);
close(fd);
return 0;
}
进程是操作系统资源分配的基本单位,每个进程都有独立的地址空间。因此,进程之间的通信需要通过操作系统提供的机制来实现。比如:管道,消息队列,共享内存,信号以及套接字。这些通信方式的本质是内核充当中间人,在内核空间中开辟一块区域,供进程之间交换数据。进程通讯也存在一些核心问题,即:
- 数据隔离:进程的地址空间是独立的,无法直接访问对方的内存。
- 同步与互斥:多个进程同时访问共享资源时,需要避免竞争条件。
- 性能与效率:不同的通信方式在速度和资源消耗上有较大差异。
另外再提一下线程之间的通讯问题。同一进程内的线程共享进程的地址空间和资源。因此,线程之间的通信可以直接通过共享内存来实现,无需内核介入。但是需要注意一下共享数据问题和同步互斥问题。
问题中的管道,是一种半双工的通信机制,数据只能单向流动。它是基于内核的缓冲区实现的,通信双方通过文件描述符来读写数据。
半双工:信息的传输是双向的;但是在任意时刻,进行信息交换的双方只有一方能进行数据传输,另一方只能进行数据接收。
匿名管道是管道的最简单形式,通常用于具有亲缘关系的进程间通信(如父子进程)。一般而言进行匿名管道的使用过程如下:
- 首先进行
pipe(int pipefd[2])的系统调用,创建匿名管道。pipefd[0]用于读,pipefd[1]用于写。其在内核中是一个环形缓冲区,默认大小是64KB(因为操作系统的不同而不同)。 - 数据流动时,数据会从
pipefd[1]写入环形缓冲区,从pipefd[0]读取并且移除环形缓冲区中的数据。如果管道为空,读操作会阻塞,直到有数据写入。如果管道已满,写操作会阻塞,直到有数据被读取。 - 当所有写端关闭时,读端会读到文件结束符。当所有读端关闭时,写端会收到
SIGPIPE信号。
需要注意的是,虽然匿名管道是可以进行双向数据流动的,但是实践中一般只是用于单向数据流动的过程。下面的代码展示了一个使用匿名管道的简单例子。
如果我们考虑在任意两个进程之间使用管道或者持久化信息通路,那么我们就会需要命名管道了。命名管道是一种特殊的文件,可以在不相关的进程之间进行通信。它通过文件系统中的路径名来标识。其实现过程与匿名管道几乎一样,只是在初始化管道和打开管道的时候有一些区别:
- 初始化管道的时候需要使用
mkfifo命令或者进行mkfifo()系统调用。 - 通过
open()系统调用来打开管道文件,读端用O_RDONLY标志,写端用O_WRONLY标志,或者用O_RDWR标志。
首先可以在命令行下执行 mkfifo test_fifo 命令,这样会创建一个名为 test_fifo 的命名管道文件。接下来可以使用 open 函数来打开这个文件,然后进行数据的读写操作。例如在一个程序中我们这样写入数据,在另外一个程序中可以这样读取数据。
Network Based 网络基础
What is the Difference between HTTP and HTTPS?
Tencent Interview Round 3 腾讯面试第三轮HTTP (Hypertext Transfer Protocol) and HTTPS (Hypertext Transfer Security Protocol) are both application-layer protocols used for transferring data between a client (such as a browser) and a server, but they fundamentally differ in terms of security, implementation mechanisms, and practical applications. HTTP, being one of the early protocols established on the internet, transmits all data in plain text, including request headers, request bodies, and server response contents. This design makes every stage of the transmission process vulnerable to interception or tampering by third parties; for instance, in public WiFi environments, attackers can easily capture users’ login credentials or sensitive information using simple packet sniffing tools. By default, HTTP operates on port 80 of the TCP protocol. Due to the lack of encryption mechanisms, neither the server nor the client can verify each other’s true identity, making man-in-the-middle attacks possible where attackers could impersonate the server or alter web content by injecting malicious scripts.
HTTPS enhances HTTP by incorporating TLS (Transport Layer Security, formerly known as SSL) to provide security assurances. When using HTTPS, all communications between the client and server are encrypted, rendering intercepted data unreadable to unauthorized parties. The encryption process begins with the TLS handshake, during which the client verifies whether the digital certificate provided by the server is issued by a trusted Certificate Authority (CA), ensuring the authenticity of the certificate and the trustworthiness of the server. Upon successful verification, the two parties negotiate to generate temporary session keys for subsequent communication encrypted using symmetric encryption algorithms like AES. This hybrid encryption mechanism ensures both security and performance efficiency. HTTPS typically uses port 443, and modern browsers indicate secure connections through a padlock icon in the address bar, while invalid or expired certificates trigger prominent warnings to prevent users from accessing phishing sites.
From a performance perspective, HTTPS theoretically consumes more computational resources and time due to additional steps for encryption/decryption and certificate validation. While early implementations of HTTPS did incur noticeable performance overhead, advancements such as hardware acceleration technologies and continuous optimizations of TLS protocols (like the significant streamlining of the handshake process in TLS 1.3) have rendered these differences negligible. In practice, when combined with the HTTP/2 protocol, HTTPS benefits from features like multiplexing and header compression, potentially leading to faster page load times compared to traditional HTTP. Moreover, since 2014, search engines like Google have considered HTTPS as a ranking signal, penalizing websites not utilizing HTTPS in search rankings. Modern browsers also restrict functionalities of HTTP websites, requiring HTTPS for access to certain APIs like geolocation or Service Workers.
In practical applications, HTTPS has become a fundamental requirement for contemporary internet use. Whether it involves e-commerce, online banking, or social media, any website dealing with user privacy or sensitive operations must deploy HTTPS. Even content-centric static websites benefit from HTTPS by preventing ISPs or malicious third parties from injecting ads or altering content. Developers can quickly implement HTTPS using free certificate services like Let’s Encrypt or opt for commercial certificates offering higher levels of validation and assurance. Additionally, strict HTTP security policies (HSTS) enforce browser connections exclusively via HTTPS, completely avoiding risks associated with plain text transmissions. In contrast, the applicability of HTTP has significantly diminished, now mainly limited to local development testing or internal networks handling non-sensitive information.
On a deeper technical level, the security mechanisms of HTTPS extend beyond mere encryption. Systems like Certificate Transparency logs monitor and audit CA-issued certificates to prevent misuse of malicious certificates; OCSP Stapling optimizes the efficiency of certificate status checks; and Forward Secrecy ensures that even if a server’s private key is compromised in the future, past communications remain secure. These measures collectively form a layered defense system for HTTPS. On the other hand, despite attempts to enhance security through extensions like digest authentication, HTTP fundamentally cannot overcome its inherent vulnerabilities stemming from plain text transmissions due to initial design oversights.
In summary, HTTPS addresses the intrinsic security flaws of HTTP through a trio of mechanisms: encrypted transmission, identity authentication, and data integrity protection. With improvements in computing power and the widespread availability of free certificate services, the cost of implementing HTTPS has significantly decreased. In today’s network environment, HTTPS is no longer optional but mandatory—it serves not only as a means to protect user privacy but also as foundational infrastructure for building a trustworthy internet ecosystem. Meanwhile, HTTP has receded into niche scenarios, retaining limited value primarily in specific edge cases. This evolution reflects a paradigm shift from prioritizing functionality to prioritizing security on the internet, highlighting the industry’s growing emphasis on data protection and user rights.
HTTP(超文本传输协议)和HTTPS(超文本传输安全协议)都是用于在客户端(如浏览器)和服务器之间传输数据的应用层协议,但它们在安全性、实现机制和实际应用上存在根本性差异。HTTP作为互联网早期制定的协议,采用明文方式传输所有数据,包括请求头、请求体以及服务器返回的响应内容。这种设计使得传输过程中的每个环节都可能被第三方监听或篡改,比如在公共WiFi环境下,攻击者可以通过简单的抓包工具轻易获取用户的登录凭证或敏感信息。HTTP默认工作在TCP协议的80端口,由于缺乏加密机制,服务器和客户端之间也无法验证对方的真实身份,这使得中间人攻击成为可能,攻击者可以伪装成服务器与客户端通信,或者篡改传输中的网页内容插入恶意代码。
HTTPS则是在HTTP基础上通过引入TLS(传输层安全协议,早期称为SSL)来提供安全保障的增强版本。当使用HTTPS时,客户端和服务器之间的所有通信都会经过加密处理,即使数据被截获,攻击者也无法解密其中的内容。HTTPS的加密过程始于TLS握手阶段,客户端会验证服务器提供的数字证书是否由受信任的证书颁发机构(CA)签发,确保证书的真实性和服务器的可信身份。验证通过后,双方会协商生成临时的会话密钥,后续通信将使用对称加密算法(如AES)进行加密,这种混合加密机制既保证了安全性又兼顾了性能。HTTPS默认使用443端口,现代浏览器会通过地址栏的锁图标直观地提示连接的安全性,而无效或过期的证书则会触发明显的警告信息,防止用户误入钓鱼网站。
从性能角度来看,HTTPS由于增加了加密解密和证书验证的步骤,理论上会比HTTP消耗更多的计算资源和时间。早期的HTTPS确实存在明显的性能开销,但随着硬件加速技术的普及和TLS协议的持续优化(如TLS 1.3大幅简化握手流程),这种差距已经变得微不足道。实际上,HTTPS配合HTTP/2协议使用时,得益于多路复用和头部压缩等特性,页面加载速度反而可能超过传统的HTTP。此外,搜索引擎如谷歌从2014年开始就将HTTPS作为排名信号之一,未启用HTTPS的网站在搜索结果中的排名会处于劣势。现代浏览器也逐渐限制HTTP网站的功能,例如地理位置API、Service Worker等特性都要求必须在HTTPS环境下才能使用。
在应用层面,HTTPS已经成为现代互联网的基础要求。无论是电子商务、在线银行还是社交媒体,任何涉及用户隐私或敏感操作的网站都必须部署HTTPS。即使是内容为主的静态网站,启用HTTPS也能防止ISP或恶意第三方注入广告或篡改内容。开发者可以通过Let’s Encrypt等免费证书服务快速部署HTTPS,或者选择商业证书获得更高级别的验证和保障。此外,严格的HTTP安全传输策略(HSTS)可以强制浏览器只通过HTTPS连接网站,彻底避免明文传输的风险。相比之下,HTTP的使用场景已经大幅萎缩,仅适用于本地开发测试或内部网络中不涉及敏感信息的服务。
从技术实现深度来看,HTTPS的安全机制不仅仅依赖于加密本身。证书透明度(Certificate Transparency)日志系统可以监控和审计CA颁发的证书,防止恶意证书的滥用;OCSP装订(OCSP Stapling)优化了证书状态检查的效率;而前向保密(Forward Secrecy)技术则确保即使服务器的私钥未来被泄露,过去的通信记录也不会被解密。这些措施共同构成了HTTPS的纵深防御体系。而HTTP由于设计之初缺乏安全考量,即便后续尝试通过摘要认证等扩展提升安全性,也无法从根本上解决明文传输的缺陷。
综上所述,HTTPS通过加密传输、身份认证和数据完整性保护三位一体的机制,彻底解决了HTTP固有的安全问题。随着计算性能的提升和免费证书服务的普及,HTTPS的实施成本已经大幅降低。在当今的网络环境中,HTTPS不再是可选项而是必选项,它既是保护用户隐私的技术手段,也是构建可信互联网生态的基础设施。而HTTP则逐渐退居幕后,仅在特定边缘场景中保留有限的使用价值。这种演进反映了互联网从功能优先到安全优先的范式转变,也体现了行业对数据保护和用户权益的日益重视。
Intelligence Questions 智力题
Generally speaking, at a later stage of the interview (between the technical short answer questions and the algorithm questions), the interviewer will ask some intelligence questions, which are usually relatively simple and can be answered with a little thought. In this section, I summarize the IQ questions I encountered when I was looking for a summer internship interview. These questions are also the questions that people encounter more often on social media.
一般来说,在面试进行到比较后面的阶段(在技术简答题和算法题之间),面试就会询问一些智力题,通常来说会比较简单,只要稍加思考便能得到答案。这个分节我总结了在我寻找暑期实习面试的时候遇到的智力题目。这些题目也是社交媒体上大家遇到得比较多的题目。
Rats and Poisons
ft.tech Interview 非凸科技面试Given $ N = 1000 $ bottles of water, where one bottle is poisoned (and the rest are normal), we aim to identify the poisoned bottle using a minimal number of mice. The rules are as follows:
- Each mouse can drink from any number of bottles (and each bottle can be sampled by multiple mice).
- Each mouse has only one opportunity to drink, and after drinking, it will either survive or die (depending on whether it drank the poisoned water).
- After one experiment (i.e., all mice drink simultaneously), the identity of the poisoned bottle must be uniquely determined based on the survival or death states of the mice.
Objective: Find the minimum number of mice $ k $ such that the survival/death states of $ k $ mice can uniquely identify which of the $ 1000 $ bottles is poisoned.
From an information theory perspective, the survival or death of each mouse provides $\log_2(2) = 1$ bit of information. To identify the poisoned bottle among $ N $ bottles, we need at least $\log_2(N)$ bits of information. Using $ k $ mice, their survival/death states can represent $ 2^k $ unique combinations. To ensure these combinations cover all $ 1000 $ bottles, we require:
\[2^k \geq 1000\]Taking the ceiling of the base-2 logarithm:
\[k = \lceil \log_2(1000) \rceil = 10\]Thus, 10 mice are sufficient to uniquely determine the poisoned bottle.
We assign each of the $ 1000 $ bottles a unique binary identifier with 10 bits (since $ 2^{10} = 1024 \geq 1000 $). For example:
- Bottle 1:
0000000001 - Bottle 5:
0000000101 - Bottle 1000:
1111101000
Each mouse corresponds to one bit position in the binary representation:
- Mouse 1 corresponds to the least significant bit (bit 1),
- Mouse 2 corresponds to bit 2,
- …, up to Mouse 10, which corresponds to the most significant bit (bit 10).
If the $ i $-th bit of a bottle’s binary representation is 1, then Mouse $ i $ drinks from that bottle. For example:
- Bottle 5 (
0000000101): Mice 1 and 3 drink from this bottle (since bits 1 and 3 are1). - Bottle 1000 (
1111101000): Mice 4, 6, 7, 8, 9, and 10 drink from this bottle (since bits 4, 6, 7, 8, 9, and 10 are1).
After the experiment, the survival or death of each mouse forms a binary sequence:
- If Mouse $ i $ dies, the $ i $-th bit in the sequence is
1. - If Mouse $ i $ survives, the $ i $-th bit in the sequence is
0.
This binary sequence corresponds to the binary representation of the poisoned bottle’s number. Converting this binary sequence to decimal gives the exact bottle number.
Suppose after the experiment, the binary sequence of mouse states is 0000011010. This corresponds to: Decimal value:
\(0 \cdot 2^9 + 0 \cdot 2^8 + 0 \cdot 2^7 + 0 \cdot 2^6 + 0 \cdot 2^5 + 1 \cdot 2^4 + 1 \cdot 2^3 + 0 \cdot 2^2 + 1 \cdot 2^1 + 0 \cdot 2^0 = 26\).
Thus, Bottle 26 is the poisoned bottle.
Using $ k = 10 $ mice, we can uniquely identify the poisoned bottle among $ 1000 $ bottles in a single experiment. This method leverages the binary encoding of bottle numbers and the survival/death states of mice to efficiently solve the problem.
给定 $ N = 1000 $ 瓶水,其中一瓶有毒(其他均为正常)。利用若干只小老鼠进行检测,规则如下:
- 每只老鼠可以喝任意多瓶水(但每瓶水可被多只老鼠喝)。
- 每只老鼠只有一次喝水机会,喝完后会存活或死亡(取决于是否喝到毒药)。
- 需在 一次实验(即所有老鼠同时喝水)后,通过老鼠的生死状态唯一确定有毒的瓶子。
目标:找到最小的老鼠数量 $ k $,使得 $ k $ 只老鼠的生死状态能唯一对应 $ 1000 $ 瓶中的某一瓶有毒。
从信息论的观点出发,每只老鼠的生死状态提供 $\log_2(2)=1$ 比特信息,因此识别 NN 瓶中的毒药需要 $\log_2(N)$ 比特信息。我们可以使用 $k$ 只老鼠的生死状态表示 $2^k$ 种唯一组合,并且当 $2^k \geq 1000$ 时,组合数足够覆盖所有可能的毒药位置。因此,最少老鼠数由计算得到 $k=⌈\log_2(1000)⌉=10$。
将 $ 1000 $ 瓶编号为 $ 1 $ 到 $ 1000 $,并转换为 10位二进制数(因 $ 2^{10} = 1024 \geq 1000 $)。例如,瓶1对应 0000000001,瓶5对应 0000000101,瓶$1000$对应 1111101000。
每只老鼠对应二进制编号中的一位,如第$1$只老鼠对应第$1$位(最低位),第$2$只对应第2位,依此类推至第$10位$(最高位)。若某瓶的二进制第 $ i $ 位为 1,则第 $ i $ 只老鼠需喝这瓶水。例如,瓶$5$(0000000101)的二进制第$1$位和第$3$位为 1,因此第$1$、$3$只老鼠喝这瓶水。瓶$1000$(1111101000)的二进制第$4$、$6$、$7$、$8$、$9$、$10$位为 1,对应第$4$、$6$、$7$、$8$、$9$、$10$只老鼠喝这瓶水。老鼠的生死状态形成一个二进制序列,若第 $ i $ 只老鼠死亡,则二进制序列第 $ i $ 位为 1;存活则为 0。将此二进制序列转换到十进制数,即为有毒瓶子的编号。
Balance and Defective Goods
Tencent Interview Round 4 腾讯面试第四轮Given nine items, where eight have the same weight and one defective item is lighter, along with a balance scale, any number of items can be placed on either side of the scale. The result of each weighing has three possible outcomes: the left side is lighter, the right side is lighter, or both sides are balanced. The goal is to identify the lighter defective item using the minimum number of weighings.
Each weighing reduces the problem size to one-third of its original size (since the scale has three possible outcomes), mathematically satisfying the equation $3^k \geq N$, where $N = 9$. Solving this gives $k = 2$ (since $3^2 = 9$). Therefore, through two weighings using a trisection method, the range is progressively narrowed down to precisely identify the defective item. This approach is applicable to similar problems (e.g., finding one item of different weight among $N$ items), and its core principle is to maximize the information entropy gained from each weighing. The specific steps are as follows:
At the first weighing, divide the nine items into three groups of three:
- Group $A$ (items ${1, 2, 3}$)
- Group $B$ (items ${4, 5, 6}$)
- Group $C$ (items ${7, 8, 9}$)
Weigh group $A$ against group $B$:
- If group $A$ is lighter $\rightarrow$ the defective item is in group $A$.
- If group $B$ is lighter $\rightarrow$ the defective item is in group $B$.
- If balanced $\rightarrow$ the defective item is in group $C$.
At the second weighing, assume that after the first weighing, the defective item is determined to be in group $X$ (where $X$ is $A$, $B$, or $C$). Take any two items from group $X$ (e.g., items $X_1$ and $X_2$) and weigh them:
- If $X_1$ is lighter $\rightarrow$ $X_1$ is the defective item.
- If $X_2$ is lighter $\rightarrow$ $X_2$ is the defective item.
- If balanced $\rightarrow$ the third item in group $X$ (i.e., $X_3$) is the defective item.
This method ensures that the defective item is identified within two weighings by systematically narrowing down the possibilities.
给定九个货物,其中八个重量相同,一个残缺货物(重量较轻),以及一个天平。可将任意数量的货物放在天平两侧,结果有三种可能:左侧较轻,右侧较轻,或者两侧重量相等。请通过最少的称量次数,找到较轻的残缺货物。
每次称量将问题规模缩小为原来的$1/3$(因天平有$3$种结果),数学上符合等式$3^k \geq N$,其中 $N=9$,解得 $k=2$(因$3^2=9$),因此通过两次称量,利用三分法逐步缩小范围,最终精确找到残缺货物。此方法适用于类似问题(如N个物品中找1个不同重量者),其核心是最大化每次称量的信息熵。具体而言,方案为:
第一次称量,将九个货物分为三组,每组三个:
- 组$A$(货物${1, 2, 3}$)
- 组$B$(货物${4, 5, 6}$)
- 组$C$(货物${7, 8, 9}$)
称量组$A$与组$B$:
- 若组$A$较轻 $\rightarrow$ 残缺货物在组$A$中。
- 若组$B$较轻 $\rightarrow$ 残缺货物在组$B$中。
- 若平衡 $\rightarrow$ 残缺货物在组$C$中。
第二次称量,假设第一次称量后,残缺货物在组$X$($X$为$A$,$B$或$C$)。从组X中任取两个货物(例如货物$X_1$和$X_2$)进行称量:
- 若$X_1$较轻 $\rightarrow$ X₁是残缺货物。
- 若$X_2$较轻 $\rightarrow$ X₂是残缺货物。
- 若平衡 $\rightarrow$ 组X中未称的第三个货物($X_3$)是残缺货物。
Water Pouring
Tencent Interview Round 2 腾讯面试第二轮Given two containers, with a capacity of 5 liters (denoted as A) and 3 liters (denoted as B), both are initially empty. The goal is to make contain exactly 4 liters of water through the following operations:
- Fill: Fill a container with water.
- Empty: Pour out all the water in a container.
- Pour: Pour water from one container to another until the source container is empty or the target container is full.
Before formally solving this problem, we need to define the states described in the problem statement. A state $(S_A, S_B)$ is defined as “A container has $S_A$ liters of water, and B container has $S_B$ liters of water.” The target state is $(4, k), k \in \mathbb{Z} \text{ and } 0 \leq k \leq 3$. We can treat this problem as a tree search problem. According to the problem description, each state has three types of state transitions, although in some special cases these transitions may overlap. From this perspective, solving this problem is equivalent to manually simulating the search process. Let’s use depth-first search with iterative depth limitation to solve it. By manually simulating, we can find the following solution:
- Fill container A completely:
\((S_A, S_B) = (5, 0)\) - Pour the water from container A into container B:
Container B is filled, and container A has $5 - 3 = 2$ liters left.
\((S_A, S_B) = (2, 3)\) - Empty container B:
\((S_A, S_B) = (2, 0)\) - Pour the remaining 2 liters of water from the 5-liter container into the 3-liter container:
\((S_A, S_B) = (0, 2)\) - Refill the 5-liter container completely:
\((S_A, S_B) = (5, 2)\) - Pour water from the 5-liter container into the 3-liter container:
The 3-liter container already has 2 liters, so it can take at most 1 more liter. After pouring 1 liter, the 5-liter container has $5 - 1 = 4$ liters left.
\((S_A, S_B) = (4, 3)\)
Thus, we can solve the state transition problem given in the problem statement. This approach can be generalized to water problems of arbitrary capacities by simply adding capacity constraints to the state transitions. Similarly, we can also use visualization methods to better solve this problem:
First, we can visualize the pair of states in a discrete plane space, using a table format. As shown in the figure below, the horizontal axis of the table represents the water volume in container A, and the vertical axis represents the water volume in container B. In this table, we can mark a path from $(4, 0)$ to $(4, 3)$, which represents the region corresponding to the target state. The current state can be treated as a point or a chess piece on the table, represented by a purple circle in the figure. The three types of transitions can be represented by arrows of different colors: blue for the first type of transition, red for the second type, and yellow for the third type. It can be seen that each transition essentially involves choosing a direction (horizontal, vertical, or sub-diagonal) and moving to a boundary point.
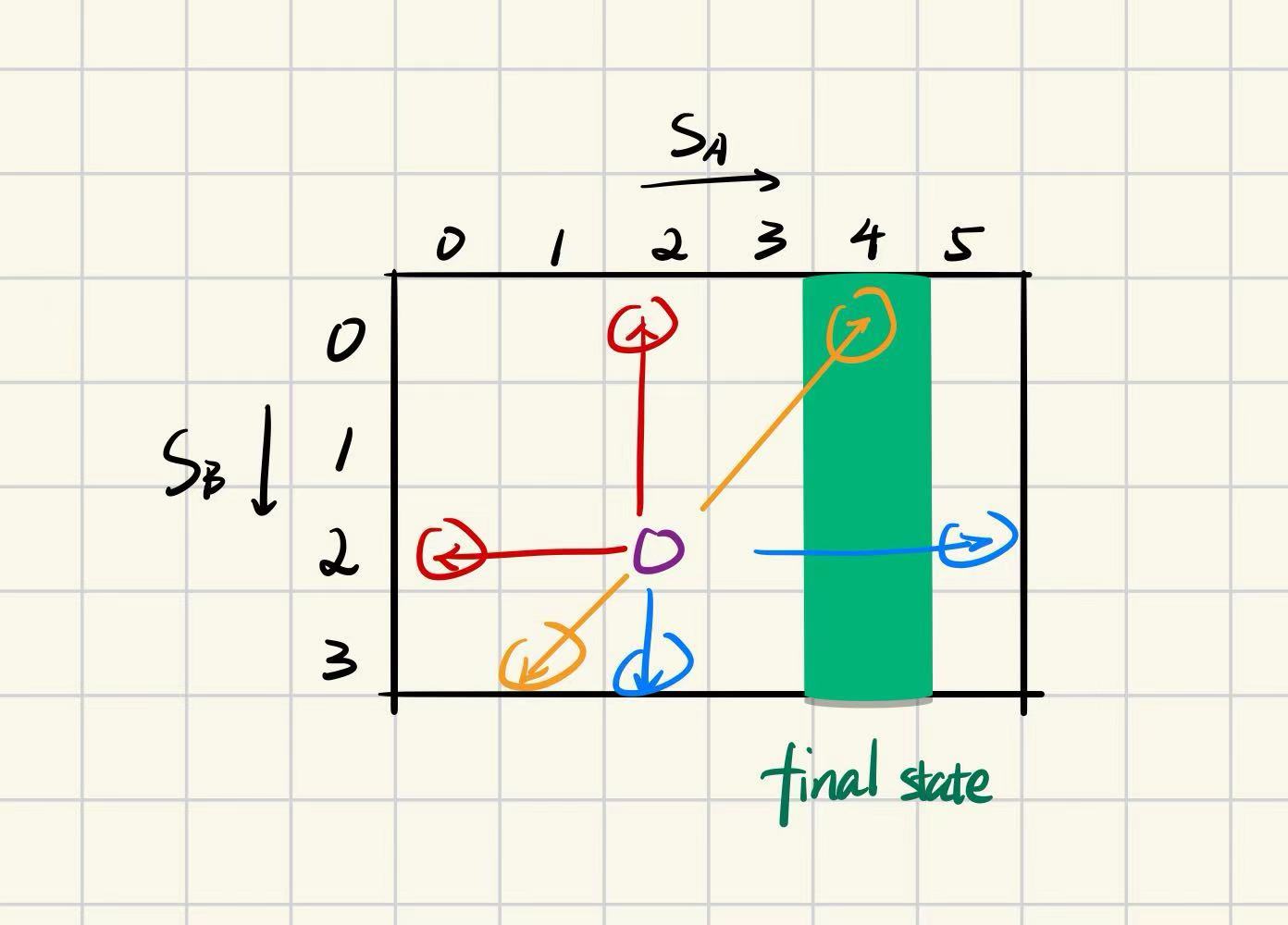
As shown in the figure below, through this visualization method, we can quickly find another valid solution. This problem-solving approach helps us find answers faster.
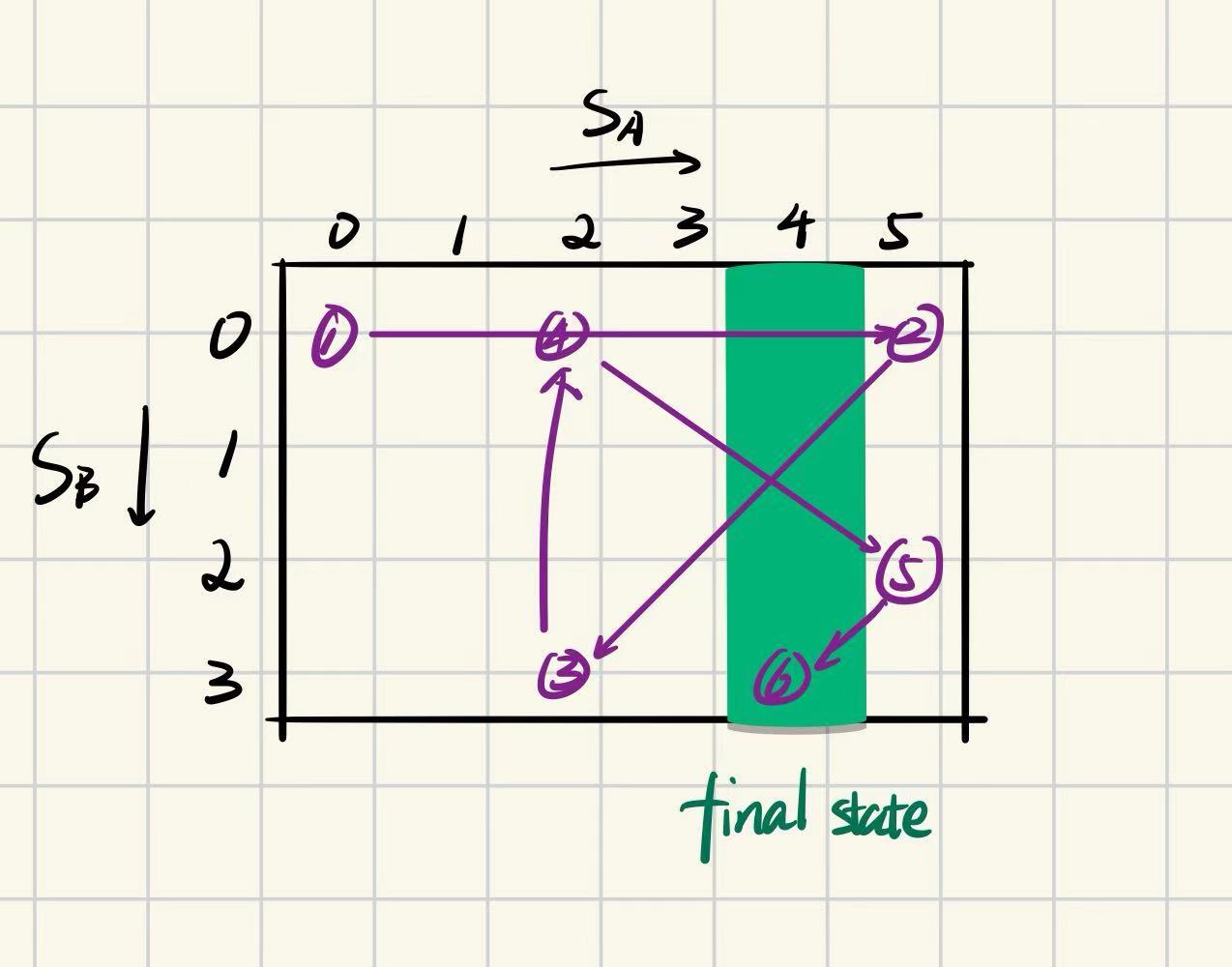
给定两个容器,容量分别为5升(记为A)和3升(记为B),初始均为空。目标是通过以下操作使A中恰好含有4升水:
- 装满:将某个容器装满水。
- 倒空:将某个容器中的水全部倒掉。
- 倒水:将水从一个容器倒入另一个容器,直到源容器为空或目标容器满。
在正式解决这个问题之前,我们需要先对问题描述中的状态进行定义。状态$(S_A, S_B)$定义为“A容器中有$S_A$升水,B容器中有$S_B$升水“,目标状态为$(4, k), k \in \mathbb{Z} \text{ and } 0 \leq k \leq 3$。我们可以将这个问题视为树上搜索问题,按照题目表述,每个状态有三类状态转移方式,当然在某些特殊情况下转移方式可能重合。从这个角度看,解决这个问题相当于是在手动模拟搜索过程,不妨我们采用深度优先搜索加迭代深度限制的方法来解决这个问题。手动模拟一下,可以找到如下方案:
- 装满A容器:
\((S_A, S_B) = (5, 0)\) - 将A容器的水倒入B容器:
B容器被填满,A容器剩余 $5 - 3 = 2$ 升。
\((S_A, S_B) = (2, 3)\) - 倒空B容器:
\((S_A, S_B) = (2, 0)\) - 将5升容器中剩余的2升水倒入3升容器:
\((S_A, S_B) = (0, 2)\) - 再次装满5升容器:
\((S_A, S_B) = (5, 2)\) - 将5升容器的水倒入3升容器:
3升容器已有2升,最多可再装1升。倒出1升后,5升容器剩余 $5 - 1 = 4$ 升。
\((S_A, S_B) = (4, 3)\)
由此,我们可以解决题目中给出的状态转移问题。这个思路可以推广到任意容量的水的问题,只需要在状态转移中加入容量限制即可。同样地,我们也可以通过可视化方法去更好完成这个问题:
首先我们对二元组状态可以在平面离散空间上进行可视化,不妨使用表格形式。如图所示,表格的横轴表示A容器的水量,纵轴表示B容器的水量。在这个表格中,我们可以标出一条从$(4, 0)$到$(4, 3)$的路径,这就是问题的目标状态代表的区域。将当前状态是视作表格上的一个点或者表格上的一个棋子,在图中我们使用紫色圆圈表示。三类转移方式我们可以使用不同颜色的箭头表示,其中蓝色表示第一种转移方式,红色表示第二种转移方式,黄色表示第三种转移方式。可以知道每次转移实际上就是选择一个方向(横向,纵向,辅对角线),然后移动到边界点。
如图所示,通过这种可视化方式我们能迅速找到另外一种合法的方案,这种解决问题的思路帮助我们更快找到答案。
Related Posts / Websites 👇
- 📑 Ray - Processes and Ray - Threads
Comments